
Stability 是明确的告诉大家,他用的是下面两篇论文:
Flow Matching for Generative Modeling ( https://arxiv.org/abs/2210.02747 )
Scalable Diffusion Models with Transformers
核心已经转向 Transformer 了

近期,最受开源社区欢迎的文生图模型 Stable Diffusion 的最新版本 Stable Diffusion 3 开放了源码和模型参数。开发者宣称,Stable Diffusion 3 使用了全新的模型结构和文本编码方法,能够生成更符合文本描述且高质量的图片。得知 Stable Diffusion 3 开源后,社区用户们纷纷上手测试,在网上分享了许多测试结果。而在本文中,我将面向之前已经熟悉 Stable Diffusion 的科研人员,快速讲解 Stable Diffusion 3 论文的主要内容及其在 Diffusers 中的源码。对于 Stable Diffusion 3 中的一些新技术,我并不会介绍其细节,而是会讲清其设计动机并指明进一步学习的参考文献。
内容索引
本文会从多个角度简单介绍 SD3,具体要介绍的方面如下所示。读者可以根据自己的需求,跳转到感兴趣的部分阅读。
流匹配原理简介
流匹配是一种定义图像生成目标的方法,它可以兼容当前扩散模型的训练目标。流匹配中一个有代表性的工作是整流 (rectified flow),它也正是 SD3 用到的训练目标。我们会在本文中通过简单的可视化示例学习流匹配的思想。
SD3 中的 DiT
我们会从一个简单的类 ViT 架构开始,学习 SD3 中的去噪网络 DiT 模型是怎么一步一步搭起来的。读者不需要提前学过 DiT,只需要了解 Transformer 的结构,并大概知道视觉任务里的 Transformer 会做哪些通用的修改(如图块化),即可学懂 SD3 里的 DiT。
SD3 模型与训练策略改进细节
除了将去噪网络从 U-Net 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进:
- 改变训练时噪声采样方法
- 将一维位置编码改成二维位置编码
- 提升 VAE 隐空间通道数
- 对注意力 QK 做归一化以确保高分辨率下训练稳定
本文会简单介绍这些改进。
大型消融实验
对于想训练大型文生图模型的开发者,SD3 论文提供了许多极有价值的大型消融实验结果。本文会简单分析论文中的两项实验结果:各训练目标在文生图任务中的表现、SD3 的参数扩增实验结果。
SD3 Diffusers 源码解读
本文会介绍如何配置 Diffusers 环境以用代码运行 SD3,并简单介绍相比于 SD,SD3 的采样代码和模型代码有哪些变动。
论文阅读
核心贡献
介绍 Stable Diffusion 3 (SD3) 的文章标题为 Scaling Rectified Flow Transformers for High-Resolution Image Synthesis。与其说它是一篇技术报告,更不如说它是一篇论文,因为它确实是按照撰写学术论文的一般思路,将正文的叙述重点放到了方法的核心创新点上,而没有过多叙述工程细节。正如其标题所示,这篇文章的内容很简明,就是用整流 (rectified flow) 生成模型、Transformer 神经网络做了模型参数扩增实验,以实现高质量文生图大模型。
由于这是一篇实验主导而非思考主导的文章,论文的开头没有太多有价值的内容。从我们读者学习论文的角度,文章的核心贡献如下:
从方法设计上:
- 首次在大型文生图模型上使用了整流模型。
- 用一种新颖的 Diffusion Transformer (DiT) 神经网络来更好地融合文本信息。
- 使用了各种小设计来提升模型的能力。如使用二维位置编码来实现任意分辨率的图像生成。
从实验上:
- 开展了一场大规模、系统性的实验,以验证哪种扩散模型/整流模型的学习目标最优。
- 开展了扩增模型参数的实验 (scaling study),以证明提升参数量能提升模型的效果。
SD3 的 MM-DiT 一开始是在 2562256^2 固定分辨率上训练的。之后在高分辨率图像上训练时,开发者用了一些巧妙的位置编码设置技巧,让不同比例的高分辨率图像也能共享之前学到的这套位置编码。详细公式请参见原论文。
训练数据预处理
看完了模块设计,我们再来看一下 SD3 在训练中的一些额外设计。在大规模训练前,开发者用三个方式过滤了数据:
- 用了一个 NSFW 过滤器过滤图片,似乎主要是为了过滤色情内容。
- 用美学打分器过滤了美学分数太低的图片。
- 移除了看上去语义差不多的图片。
虽然开发者们自信满满地向大家介绍了这些数据过滤技术,但根据社区用户们的反馈,可能正是因为色情过滤器过分严格,导致 SD3 经常会生成奇怪的人体。
由于在训练 LDM 时,自编码器和文本编码器是不变的,因此可以提前处理好所有训练数据的图像编码和文本编码。当然,这是一项非常基础的工程技巧,不应该写在正文里的。
用 QK 归一化提升训练稳定度
按照之前高分辨率文生图模型的训练方法,SD3 会先在 2562256^2 的图片上训练,再在高分辨率图片上微调。然而,开发者发现,开始微调后,混合精度训练常常会训崩。根据之前工作的经验,这是由于注意力输入的熵会不受控制地增长。解决方法也很简单,只要在做注意力计算之前对 Q, K 做一次归一化就行,具体做计算的位置可以参考上文模块图中的 “RMSNorm”。不过,开发者也承认,这个技巧并不是一个长久之策,得具体问题具体分析。看来这种 DiT 模型在大规模训练时还是会碰到许多训练不稳定的问题,且这些问题没有一个通用解。
哪种扩散模型训练目标最适合文生图任务?
最后我们来看论文的实验结果部分。首先,为了寻找最好的扩散模型/流匹配模型,开发者开展了一场声势浩大的实验。实验涉及 61 种训练公式,其中的可变项有:
- 对于普通扩散模型,考虑 ϵ\epsilon- 或 v\mathbf{v}-prediction,考虑线性或 cosine 噪声调度。
- 对于整流,考虑不同的噪声调度。
- 对于 EDM,考虑不同的噪声调度,且尽可能与整流的调度机制相近以保证可比较。
在训练时,除了训练目标公式可变外,优化算法、模型架构、数据集、采样器都不可变。所有模型在 ImageNet 和 CC12M 数据集上训练,在 COCO-2014 验证集上评估 FID 和 CLIP Score。根据评估结果,可以选出每个模型的最优停止训练的步数。基于每种目标下的最优模型,开发者对模型进行最后的排名。由于在最终评估时,仍有采样步数、是否使用 EMA 模型等可变采样配置,开发者在所有 24 种采样配置下评估了所有模型,并用一种算法来综合所有采样配置的结果,得到一个所有模型的最终排名。最终的排名结果如下面的表 1 所示。训练集上的一些指标如表 2 所示。
Diffusers 源码阅读
测试脚本
我们来阅读一下 SD3 在最流行的扩散模型框架 Diffusers 中的源码。在读源码前,我们先来跑通官方的示例脚本。
由于使用协议的限制,SD3 的环境搭起来稍微有点麻烦。首先,我们要确保 Diffuers 和 Transformers 都用的是最新版本。
pip install --upgrade diffusers transformers
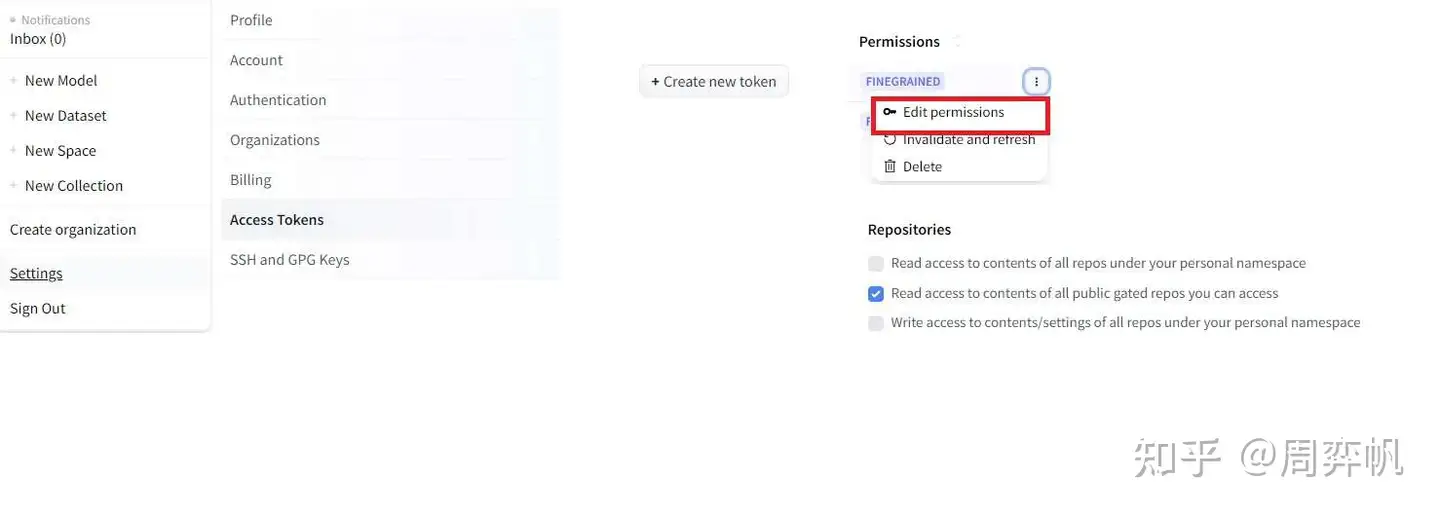
之后,我们要注册 HuggingFace 账号,再在 SD3 的模型网站 https://huggingface.co/stabilityai/stable-diffusion-3-medium 里确认同意某些使用协议。之后,我们要设置 Access Token。具体操作如下所示,先点右上角的 “settings”,再点左边的 “Access Tokens”,创建一个新 token。将这个 token 复制保存在本地后,点击 token 右上角选项里的 “Edit Permission”,在权限里开启 “… public gated repos …”。
最后,我们用命令行登录 HuggingFace 并使用 SD3。先用下面的命令安装 HuggingFace 命令行版。
pip install -U "huggingface_hub[cli]"
再输入 huggingface-cli login,命令行会提示输入 token 信息。把刚刚保存好的 token 粘贴进去,即可完成登录。
huggingface-cli login
Enter your token (input will not be visible): 在这里粘贴 token
做完准备后,我们就可以执行下面的测试脚本了。注意,该脚本会自动下载模型,我们需要保证当前环境能够访问 HuggingFace。执行完毕后,生成的 1024×10241024 \times 1024 大小的图片会保存在 tmp.png 里。
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained(
"stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
image = pipe(
"A cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
).images[0]
image.save('tmp.png')
我得到的图片如下所示。看起来 SD3 理解文本的能力还是挺强的。

模型组件
接下来我们来快速浏览一下 SD3 流水线 StableDiffusion3Pipeline 的源码。在 IDE 里使用源码跳转功能可以在 diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3.py 里找到该类的源码。
通过流水线的 __init__ 方法,我们能知道 SD3 的所有组件。组件包括自编码器 vae, MM-DiT Transformer, 流匹配噪声调度器 scheduler,以及三个文本编码器。每个编码器由一个 tokenizer 和一个 text encoder 组成.
def __init__(
self,
transformer: SD3Transformer2DModel,
scheduler: FlowMatchEulerDiscreteScheduler,
vae: AutoencoderKL,
text_encoder: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer_2: CLIPTokenizer,
text_encoder_3: T5EncoderModel,
tokenizer_3: T5TokenizerFast,
):
vae 的用法和之前 SD 的一模一样,编码时用 vae.encode 并乘 vae.config.scaling_factor,解码时除以 vae.config.scaling_factor 并用 vae.decode。
文本编码器的用法可以参见 encode_prompt 方法。文本会分别过各个编码器的 tokenizer 和 text encoder,得到三种文本编码,并按照论文中的描述拼接成两种约束信息。这部分代码十分繁杂,多数代码都是在处理数据形状,没有太多有价值的内容。
def encode_prompt(
self,
prompt,
prompt_2,
prompt_3,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
negative_prompt_2,
negative_prompt_3,
...
):
...
return prompt_embeds, negative_prompt_embeds,
pooled_prompt_embeds, negative_pooled_prompt_embeds
采样流水线
我们再来通过阅读流水线的 __call__ 方法了解 SD3 采样的过程。由于 SD3 并没有修改 LDM 的这套生成框架,其采样流水线和 SD 几乎完全一致。SD3 和 SD 的 __call__ 方法的主要区别是,生成文本编码时会生成两种编码。
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(...)
在调用去噪网络时,那个较小的文本编码 pooled_prompt_embeds 会作为一个额外参数输入。
noise_pred = self.transformer(
hidden_states=latent_model_input,
timestep=timestep,
encoder_hidden_states=prompt_embeds,
pooled_projections=pooled_prompt_embeds,
joint_attention_kwargs=self.joint_attention_kwargs,
return_dict=False,
)[0]
MM-DiT 去噪模型
相比之下,SD3 的去噪网络 MM-DiT 的改动较大。我们来看一下对应的 SD3Transformer2DModel 类,它位于文件 diffusers\models\transformers\transformer_sd3.py。
类的构造函数里有几个值得关注的模块:二维位置编码类 PatchEmbed、组合时刻编码和文本编码模块 CombinedTimestepTextProjEmbeddings、主模块类 JointTransformerBlock。
def __init__(...):
...
self.pos_embed = PatchEmbed(...)
self.time_text_embed = CombinedTimestepTextProjEmbeddings(...)
...
self.transformer_blocks = nn.ModuleList(
[
JointTransformerBlock(..)
for i in range(self.config.num_layers)
]
)
类的前向传播函数 forward 里都是比较常规的操作。数据会依次经过前处理、若干个 Transformer 块、后处理。所有实现细节都封装在各个模块类里。
def forward(...):
hidden_states = self.pos_embed(hidden_states)
temb = self.time_text_embed(timestep, pooled_projections)
encoder_hidden_states = self.context_embedder(encoder_hidden_states)
for index_block, block in enumerate(self.transformer_blocks):
encoder_hidden_states, hidden_states = block(...)
encoder_hidden_states, hidden_states = block(
hidden_states=hidden_states, encoder_hidden_states=encoder_hidden_states, temb=temb
)
...
接下来我们来看这几个较为重要的子模块。PatchEmbed 类的实现写在 diffusers/models/embeddings.py 里。这个类的实现写得非常清晰。PatchEmbed 类本身用于维护位置编码宽高、特征长度这些信息,计算位置编码的关键代码在 get_2d_sincos_pos_embed 中。get_2d_sincos_pos_embed 会生成 (0, 0), (1, 0), ... 这样的二维坐标网格,再调用 get_2d_sincos_pos_embed_from_grid 生成二维位置编码。get_2d_sincos_pos_embed_from_grid 会调用两次一维位置编码函数 get_1d_sincos_pos_embed_from_grid,也就是 Transformer 里那种标准位置编码生成函数,来分别生成两个方向的编码,最后拼接成二维位置编码。
class PatchEmbed(nn.Module):
...
def forward(self, latent):
...
pos_embed = get_2d_sincos_pos_embed(...)
def get_2d_sincos_pos_embed(...):
grid_h = np.arange(...)
grid_w = np.arange(...)
grid = np.meshgrid(grid_w, grid_h)
...
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
def get_2d_sincos_pos_embed_from_grid(...):
# use half of dimensions to encode grid_h
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
return emb
组合时刻编码和文本编码模块 CombinedTimestepTextProjEmbeddings 的代码非常短。它实际上就是用通常的 Timesteps 类获取时刻编码,用一个 text_embedder 模块再次处理文本编码,最后把两个编码加起来。 text_embedder 是一个线性层、激活函数、线性层构成的简单模块。
class CombinedTimestepTextProjEmbeddings(nn.Module):
def __init__(self, embedding_dim, pooled_projection_dim):
super().__init__()
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
self.text_embedder = PixArtAlphaTextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
def forward(self, timestep, pooled_projection):
timesteps_proj = self.time_proj(timestep)
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
pooled_projections = self.text_embedder(pooled_projection)
conditioning = timesteps_emb + pooled_projections
return conditioning
class PixArtAlphaTextProjection(nn.Module):
def __init__(...):
...
def forward(self, caption):
hidden_states = self.linear_1(caption)
hidden_states = self.act_1(hidden_states)
hidden_states = self.linear_2(hidden_states)
return hidden_states
MM-DiT 的主要模块 JointTransformerBlock 在 diffusers/models/attention.py 文件里。这个类的代码写得比较乱。它主要负责处理 LayerNorm 及数据的尺度变换操作,具体的注意力计算由注意力处理器 JointAttnProcessor2_0 负责。两处 LayerNorm 的实现方式竟然是不一样的。
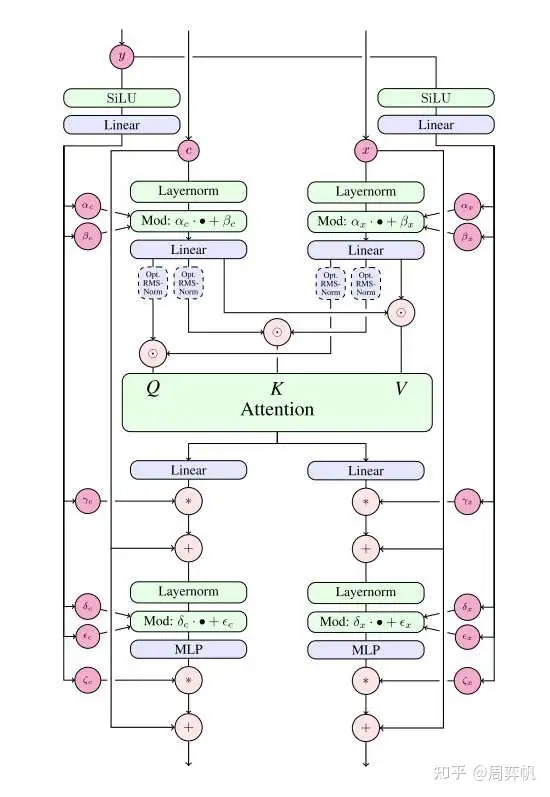
我们先简单看一下构造函数里初始化了哪些模块。代码中,norm1, ff, norm2 等模块都是普通 Transformer 块中的模块。而加了 _context 的模块则表示处理文本分支 cc 的模块,如 norm1_context, ff_context。context_pre_only 表示做完了注意力计算后,还要不要给文本分支加上 LayerNorm 和 FeedForward。如前文所述,具体的注意力计算由 JointAttnProcessor2_0 负责。
class JointTransformerBlock(nn.Module):
def __init__(self, dim, num_attention_heads, attention_head_dim, context_pre_only=False):
super().__init__()
self.context_pre_only = context_pre_only
context_norm_type = "ada_norm_continous" if context_pre_only else "ada_norm_zero"
self.norm1 = AdaLayerNormZero(dim)
if context_norm_type == "ada_norm_continous":
self.norm1_context = AdaLayerNormContinuous(
dim, dim, elementwise_affine=False, eps=1e-6, bias=True, norm_type="layer_norm"
)
elif context_norm_type == "ada_norm_zero":
self.norm1_context = AdaLayerNormZero(dim)
processor = JointAttnProcessor2_0()
self.attn = Attention(
query_dim=dim,
cross_attention_dim=None,
added_kv_proj_dim=dim,
dim_head=attention_head_dim,
heads=num_attention_heads,
out_dim=dim,
context_pre_only=context_pre_only,
bias=True,
processor=processor,
)
self.norm2 = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
self.ff = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
if not context_pre_only:
self.norm2_context = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
self.ff_context = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
else:
self.norm2_context = None
self.ff_context = None
我们再来看 forward 方法。在前向传播时,图像分支和文本分支会分别过 norm1,再一起过注意力操作,再分别过 norm2 和 ff。大概的代码如下所示,我把较复杂的 context 分支的代码略过了。
这份代码写得很不漂亮,按理说模块里两个 LayerNorm + 尺度变换 (即 Adaptive LayerNorm) 的操作是一样的,应该用同样的代码来处理。但是这个模块里 norm1 是 AdaLayerNormZero 类,norm2 是 LayerNorm 类。norm1 会自动做完 AdaLayerNorm 的运算,并把相关变量返回。而在 norm2 处,代码会先执行普通的 LayerNorm,再根据之前的变量手动调整数据的尺度。我们心里知道这份代码是在实现论文里那张结构图就好,没必要去仔细阅读。
def forward(
self, hidden_states: torch.FloatTensor, encoder_hidden_states: torch.FloatTensor, temb: torch.FloatTensor
):
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb)
if self.context_pre_only:
...
# Attention.
attn_output, context_attn_output = self.attn(
hidden_states=norm_hidden_states, encoder_hidden_states=norm_encoder_hidden_states
)
# Process attention outputs for the `hidden_states`.
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = hidden_states + attn_output
norm_hidden_states = self.norm2(hidden_states)
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = hidden_states + ff_output
if self.context_pre_only:
...
return encoder_hidden_states, hidden_states
融合注意力的实现方法很简单。和普通的注意力计算相比,这种注意力就是把另一条数据分支 encoder_hidden_states 也做了 QKV 的线性变换,并在做注意力运算前与原来的 QKV 拼接起来。做完注意力运算后,两个数据又会拆分回去。
class JointAttnProcessor2_0:
"""Attention processor used typically in processing the SD3-like self-attention projections."""
def __call__(
self,
attn: Attention,
hidden_states: torch.FloatTensor,
encoder_hidden_states: torch.FloatTensor = None,
attention_mask: Optional[torch.FloatTensor] = None,
*args,
**kwargs,
) -> torch.FloatTensor:
...
# `sample` projections.
query = attn.to_q(hidden_states)
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
# `context` projections.
encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
# attention
query = torch.cat([query, encoder_hidden_states_query_proj], dim=1)
key = torch.cat([key, encoder_hidden_states_key_proj], dim=1)
value = torch.cat([value, encoder_hidden_states_value_proj], dim=1)
...
# Split the attention outputs.
hidden_states, encoder_hidden_states = (
hidden_states[:, : residual.shape[1]],
hidden_states[:, residual.shape[1] :],
)
总结
在这篇文章中,我们学习了 SD3 论文及源码中的主要内容。相比于 SD,SD3 做了两项较大的改进:用整流代替原来的 DDPM 中的训练目标;将去噪模型从 U-Net 变成了能更好地处理多模态信息的 MM-DiT。SD3 还在模型结构和训练目标上做了许多小改进,如调整训练噪声采样分布、使用二维位置编码。SD3 论文展示了多项大型消融实验的结果,证明当前的 SD3 是以最优配置训练得到的。SD3 可以在 Diffusers 中使用。当然,由于 SD3 的使用协议较为严格,我们需要做一些配置,才能在代码中使用 SD3。SD3 的采样流水线基本没变,原来 SD 的多数编辑方法能够无缝迁移过来。而 SD3 的去噪模型变动较大,和 U-Net 相关的编辑方法则无法直接用过来。在学习源码时,主要值得学习的是新 MM-DiT 模型中每个 Transformer 层的实现细节。
尽管 SD3 并没有提出新的流匹配方法,但其实验结果表明流匹配模型可能更适合文生图任务。作为研究者,受此启发,我们或许需要关注一下整流等流匹配模型,知道它们的思想,分析它们与原扩散模型训练目标的异同,以拓宽自己的视野。
作者:周弈帆
链接:https://www.zhihu.com/question/645441220/answer/3561048626
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
叫我Alonzo就好了
https://www.zhihu.com/question/645441220
https://stability.ai/news/stable-diffusion-3
Diffusion Transformer:关于Sora和Stable Diffusion 3你需要知道的一切



研究动机
Stable Diffusion 3的研究动机其实是从数据加噪的forward路径上出发的。作者指出,如果forward路径并非最优路径,那么就会导致扩散模型在训练过程中没有办法从输入加噪数据中完全去除噪声,那么在测试的过程中,模型就会生成一些带有artifacts的结果,例如灰度图像[2]。
特别地,forward的选择也会影响backward路径的计算复杂度,也就是采样效率(sampling efficiency),进一步影响到图片生成的速度。
尽管我们可以整合额外采样步数,通过曲线路径来尽可能地仿真最优路径,但是曲线路径仍然存在错误累计的问题。对此,直线路径(也就是通过一步直接进行仿真)会减少错误累积的发生。
对于这个问题,有一个特别的解决方案,也就是rectified flow[3]。recitified flow已经在小中型的实验上证明了其有效性,而在Stable Diffusion 3的设定中,模型规模从800M进一步扩大至了8B,这项技术在大规模实验上的有效性亟待证明,这也是Stable Diffusion 3这篇工作的创新点之一。
Stable Diffusion 3从模型forward的过程出发展开研究,读完intro之后的第一感觉就是不得不佩服这群人的理论功底和调研能力。forward过程的研究,属于是大家都知道可以做,但是非常难做的类型,不是仅仅做好工程问题就能搞定的。forward过程跟backward过程往往紧密相连,一旦改动了diffusion model的forward过程,那就意味着backward过程的目标也要进行调整,只有对于diffusion model的全生命周期熟稔于心的团队才能handle这样的创新。
技术路线
技术路线的解读分为两个方面进行,一是关于flow matching的改进;另一方面是在Diffusion Transformer上的具体设计。
Simulation-Free Training of Flows
这里直接沿用了原文的章节标题,也非常言简意骇。「Simulation-Free」指的是扩散模型的模型参数不再用来直接拟合带噪数据和干净数据分布之间的映射关系,而是通过拟合一个向量场,通过这个向量场将加噪/去噪过程给联系起来。「Flows」指代的就是通过flow matching的技术来实现这件事。本质上,retified flow对diffusion model原本的运作方式进行了降维,进而提升了forward、backward过程的一致性以及采样过程的效率,与Stable Diffusion 3的研究动机相契合。
关于rectified flow会怎样影响diffusion model的损失函数,原文中给了详尽的推导过程,补充材料中也给了严谨的数学证明,这里就不再一一赘述。
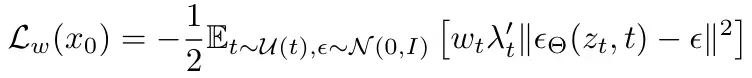
除了rectified flow之外,文章还简单阐述了几种其他的变式的forward过程,这里也不再具体展开。

前面说到,在对forward过程进行修改过后,也要同时对backward过程进行调整。Stable Diffusion 3的做法则是提出了定制化的采样策略,希望模型在采样的过程中,在中间的步数拥有更高的权重。这里,Stable Diffusion 3提出了一个密度函数,通过对每一步的scale和bias进行控制来重新调整采样的分布。
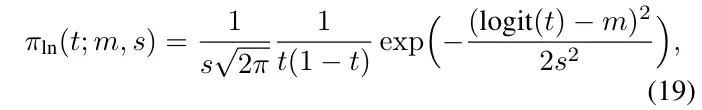
对于这类型看似非常晦涩难懂的公式,有一部分工作可能是依赖大量的工程经验得来的,也就是说经过大量的实验试错,因此往往很难得到有效的定性结论。同样地,由于笔者本人水平有限,在此的相关分析及讨论也仅作参考。
值得注意的是,这里说到的中间采样部署权重过低的问题。其实在T2I-Adapter[4]这篇工作中也有明确指出:Stable diffusion在生成图片的时候,重要的采样步数主要集中在采样过程的前半段,因此在前半段加入控制才是最合适的。而Stable Diffusion 3从rectified flow的角度重新address了这个问题。
针对于cosine的噪声策略,Stable Diffusion 3也提出了相应的密度函数公式。这里值得注意的一个点是对于扩散模型关于timestep采样策略的改进,原本的扩散模型timestep是从 [0,T] 的均匀分布中采样得到,而Stable Diffusion 3中不再对timestep进行均匀采样,而是从非线性分布中进行采样,同理也可以获得cosine噪声策略下的密度函数。
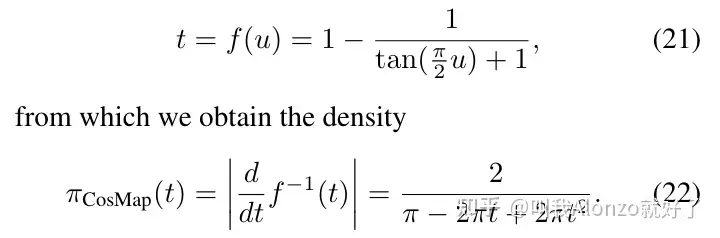
MM-DiT
RMS-Norm。Stable Diffusion 3的另外一个创新点就是在每一个attention运算之前,对Q和K进行了RMS-Norm归一化,用于增强模型训练的稳定性。
通过Image Copy Detection去除数据冗余
另一个比较有意思的发现是扩散模型倾向于记住训练中出现的样本,因此对数据中冗余的、重复出现的数据样本进行清洗很有必要,Stable Diffusion 3也设计了具体的数据清洗方案。具体来说,Stable Diffusion 3借助SSCD[7]的image copy generation方法来实现这一点,具体流程在原文中提供了详尽的分析及伪代码,需要的朋友可以自取。


结语
Stable Diffusion 3除去Diffusion Transformer的架构设计之外,在forward过程的改进、sampling过程的设计、压缩模型、captions、数据清洗等多个角度展现了其独到之处,无论是从工程项目还是从学术研究的角度来看,都有许多的可取之处。Stable Diffusion 3能否在CVPR 2022年的Latent Diffusion Models那样给CV社区重新注入活力,乃至给文生视频领域更多的启发?让我们拭目以待。
Text-to-Image Generation Paper List
github.com/AlonzoLeeeooo/awesome-text-to-image-studies
Video Generation Paper List
github.com/AlonzoLeeeooo/awesome-video-generation
参考
- ^Scaling Rectified Flow Transformers for High-Resolution Image Synthesis https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
- ^Common Diffusion Noise Schedules and Sample Steps are Flawed https://arxiv.org/abs/2305.08891
- ^Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow https://arxiv.org/abs/2209.03003
- ^T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models https://arxiv.org/abs/2302.08453
- ^Improving Image Generation with Better Captions https://cdn.openai.com/papers/dall-e-3.pdf
- ^Late-Constraint Diffusion Guidance for Controllable Image Synthesis https://arxiv.org/abs/2305.11520
- ^A Self-Supervised Descriptor for Image Copy Detection https://arxiv.org/abs/2202.10261