网上几乎所有资料介绍transformer时都只是解释了Q K V的公式,然后基本就结束了。我看到现在还是不理解。神经网络很好理解,本质上是通过反向传播调整W和B参数,使模型能够拟合数据。但transformer的反向传播呢?如何调整权重参数?
像我这种业余的AI爱好者而不熟悉 NLP 的人来说,第一次看到 Attention is all you need 的论文是一脸懵逼的,它的架构远比CNN、MLP、RNN这些复杂多了。
不过后来了解了一些前因后果之后,还是摸到了一点线索。Transformer 结构的很多设计,都是为了解决NLP之前模型(比如RNN、Seq2Seq)的问题,如果不了解这些问题的话就不能理解为什么要这么设计。为此,有必要对 NLP 任务的一些特点进行全面回顾。
1 自然语言处理基本概念
自然语言处理技术 (Natural Language Processing, NLP) 的基本目标是读懂一句话。这里的一句话,在电脑中被建模成一个序列,其中的每个元素是一个词元 (token)。自然语言处理技术主要包括以下目标:
- 词法分析:将句子中的词元进行分类,比如名词、动词、代词等。
- 句法分析:将句子中的词元进行组合,比如名词短语、句子等。
- 语义分析:根据句子中的词元,判断句子的语义。
- 机器翻译:根据输入的句子,输出具有相同含义的另一种语言的句子。
- 文本生成:根据输入的提示词续写文本。
- 机器对话:根据输入的用户提问,输出对应的回答。
如果模型能完全读懂一个句子,那么以上问题就可以解决。
在计算机视觉领域,人们习惯于将基本的图像分类模型作为基础骨架来完成其他任务。但是在 NLP 中,对词法的准确分析难度很高,而且即使能够做到准确的词法分析,依然难以理解句子的完整语义。这是因为自然语言往往具有非常长程的关联关系,某个词的语义可能由整个输入文本共同决定。
因此,现在人们倾向于抛弃那些着眼于文本局部特征的任务,像是词法、句法、语义分析之类的,而直接用大模型完成那些需要关注全局语义的文本生成、机器对话等任务。实践表明,这样反而取到了更好的效果。
1.1 词元
最简单的想法是,英语中的一个单词或者中文中的一个字,就是一个词元。但实际上,词元的划分要更加复杂一点,一个单词或字可能由多个词元表示,某些词元也可以表示多个单词或者多个字。
不论如何,词元可能的种类数量是有限的,所以可以把它们编制成词表,起到类似字典的作用。这样,就可以用词表中的某个序号来唯一表示某个词元了,从而完成对自然语言的数字化。这种方案和 Unicode 编码表有点类似,只不过编码表是严格的一个字符对应一个序号,而词表则是根据自然语言的规律确定的,与具体的模型选择有关。
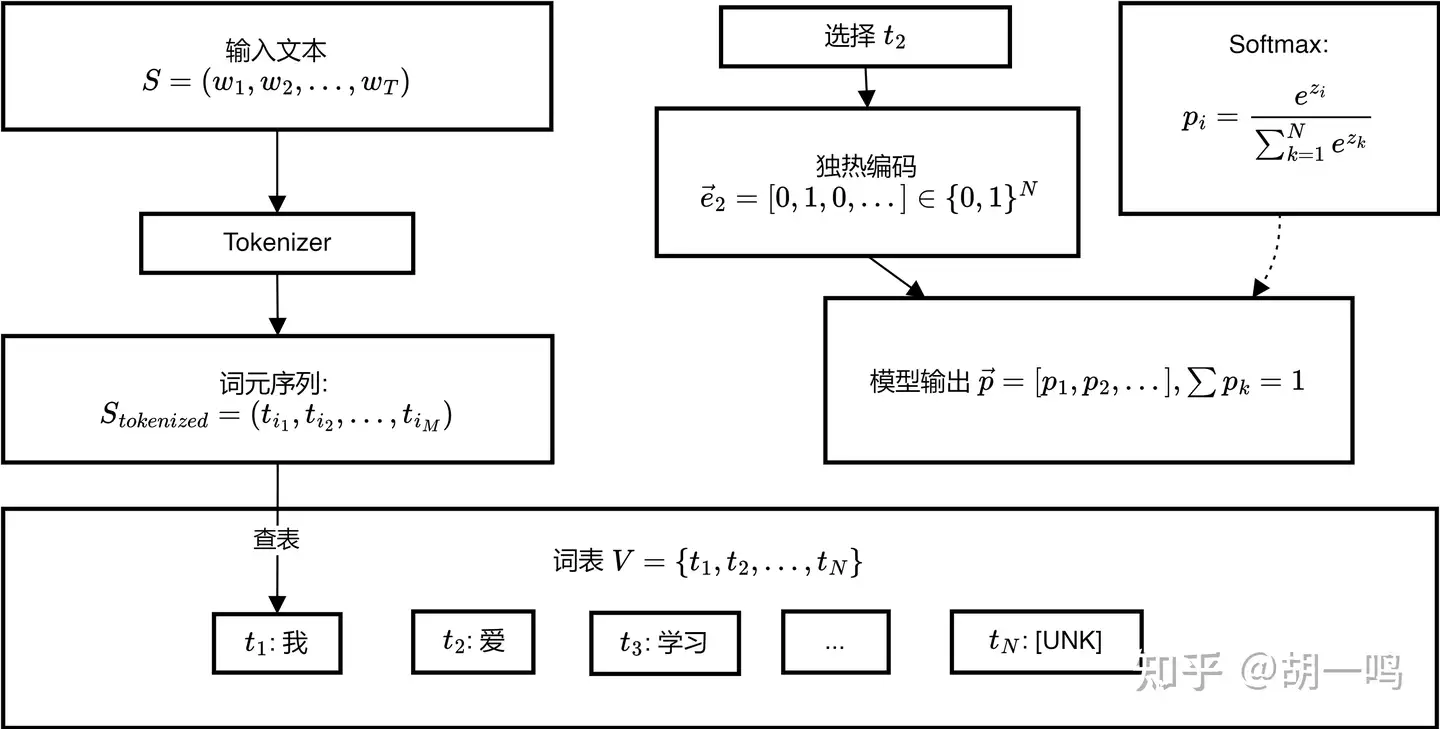
设词表为 V=t1,t2,…,tN ,其中 N 为词表大小, ti 表示第 i 个词元。对于输入文本序列 S=(w1,w2,…,wT) ,经过分词器处理后得到词元序列:
其中Stokenized=(ti1,ti2,...,tiM)其中 tik∈V S_{\text{tokenized}} = (t_{i_1}, t_{i_2}, ..., t_{i_M}) \quad \text{其中} \ t_{i_k} \in V 例如,“原神启动”就可以这样变为 {342,645,7544} ,分别为 “原”、“神”、“启动”三个词元在词表中的序号。
仅仅是序号仍不适合作为神经网络的输入和输出,因为这是一种整数量,而词表的前后关系一般来说并不具有特别明显的数学运算意义。
如果把”选择某个词元”这件事情看作是分类问题 (而不是回归问题) 的话,那么生成自然语言的模型输出,就应当是一个离散的概率分布而不是一个序号。和图像分类一样,这种输出是一个向量,每个元素表示对应序号的词元的概率。对于确定的结果,那么就是对应的数字为 1 而其他数字为 0。这就自然引出了独热 (One-hot) 编码:用一个和词表长度一样长的向量来表示,它哪个元素是1就表示这是哪个词元:
第位ei=[0,…,0,1⏟第i位,0,…,0]∈{0,1}N
\mathbf{e}_i = [0,...,0,\underbrace{1}_{\text{第}i\text{位}},0,...,0] \in \{0,1\}^N \mathbf{e}_i = [0,...,0,\underbrace{1}_{\text{第}i\text{位}},0,...,0] \in \{0,1\}^N 其中 ei 表示第 i 个词元的独热编码向量,满足 |ei|1=1 。当模型预测结果为概率分布 p∈[0,1]N 时,需满足 ∑k=1Npk=1 ,这通常通过softmax函数实现:
pi=ezi∑k=1Nezk
p_i = \dfrac{e^{z_i}}{\sum_{k=1}^N e^{z_k}} p_i = \dfrac{e^{z_i}}{\sum_{k=1}^N e^{z_k}} 其中 zi 为模型对第 i 个词元的原始输出分数。
1.2 词向量
要想让词元的数学运算关系更加明确一点的话,就需要使用词向量。它通过把词元对应到一个固定的向量中,从而让词元的语义能和向量的数学运算 (加法和数乘) 对应起来。给定词表 V ,每个词 w 都会对应到词向量 v→w∈Rd ,其中 d 为词向量维度。
词向量空间中的几何关系,就表示了词的语义信息。例如类比关系可表示为:
国王男人女人女王ϕ(“国王”)−ϕ(“男人”)+ϕ(“女人”)≈ϕ(“女王”)
\phi(\text{"国王"}) - \phi(\text{"男人"}) + \phi(\text{"女人"}) \approx \phi(\text{"女王"}) \phi(\text{"国王"}) - \phi(\text{"男人"}) + \phi(\text{"女人"}) \approx \phi(\text{"女王"}) 其中 ϕ 是把词元映射为词向量的函数。
词向量的有效性源于分布式假设:具有相似上下文的词具有相似语义。通过最小化预测误差,模型迫使语义相近的词在向量空间中彼此靠近,同时保持词对间的方向关系对应语义关系。相比于高度稀疏、占空间的独热编码,词向量维度较低、紧凑,而且具有一定的数学结构,天然适合于优化计算 (也就是模型训练)。这种表示方法为后续的神经网络语言模型奠定了基础。
在数学中,Embedding (嵌入) 是一种特殊的映射,其核心目标是保留原空间的结构或性质,同时将对象映射到另一个(通常是更低维或更简单的)空间中。在这里我们也是把高维但稀疏的词元编号 (独热编码) 映射到低维的词向量空间中,因此词向量也常常被成为词嵌入 (Word Embedding)。
2 循环神经网络
循环神经网络 (Recurrent Neural Network, RNN) 是一种专门用于处理序列数据的神经网络架构。给定输入序列 X→=(x→1,x→2,…,x→T) ,其中 x→t∈Rd 表示第 t 个时间步的输入向量, d 为输入特征维度, T 为序列长度。在自然语言处理中, x→t 就是一个词元所对应的词向量,而 d 就是词向量的维度。
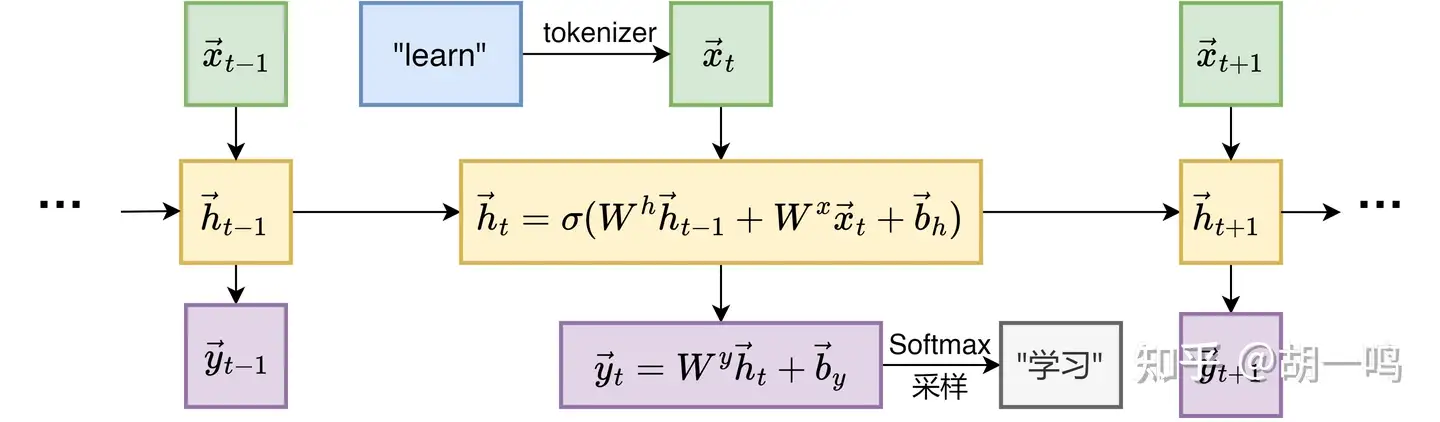
RNN通过引入隐藏状态 h→t∈Rdh 来捕捉序列的时序信息,其中 dh 为隐藏状态维度。在每个时间步 t ,RNN根据当前输入 x→t 和前一时刻的隐藏状态 h→t−1 计算当前隐藏状态:
h→t=σ(Whh→t−1+Wxx→t+b→h)
\vec{h}_t = \sigma(W^{h} \vec{h}_{t-1} + W^{x} \vec{x}_t + \vec{b}_h) \vec{h}_t = \sigma(W^{h} \vec{h}_{t-1} + W^{x} \vec{x}_t + \vec{b}_h) W^{h} \in \mathbb{R}^{d_h \times d_h}, 为隐藏状态权重矩阵,
W^{x} \in \mathbb{R}^{d_h \times d}, 为输入权重矩阵,
\vec{b}_h \in \mathbb{R}^{d_h}, 为偏置项, 其中 Wh∈Rdh×dh 为隐藏状态权重矩阵, Wx∈Rdh×d 为输入权重矩阵, b→h∈Rdh 为偏置项, σ 为激活函数(通常为tanh或ReLU)。输出 y→t∈Rm 通过以下公式计算:
y→t=Wyh→t+b→y
\vec{h}_t = \sigma(W^{h} \vec{h}_{t-1} + W^{x} \vec{x}_t + \vec{b}_h) \vec{h}_t = \sigma(W^{h} \vec{h}_{t-1} + W^{x} \vec{x}_t + \vec{b}_h) 其中 Wy∈RN×dh 为输出权重矩阵, b→y∈RN 为输出偏置项, N 为输出维度。
W^{y} \in \mathbb{R}^{N \times d_h}, 为输出权重矩阵, \vec{b}_y \in \mathbb{R}^N, 为输出偏置项, 这种结构使得RNN能够处理任意长度的序列,并通过隐藏状态在时间步之间传递信息,从而捕捉序列中的长期依赖关系。一般来说,对于生成字符的应用,比如机器翻译而言, N 是词表的长度,而 yt(n) 就对应于词表中第 n 个词元的概率分数 (因而 y→t 的意义及维度和输入词元的向量 x→t 完全不同)。
3 序列到序列模型
传统 RNN 每读取一个词元,就要输出一个词元,输入和输出序列长度必须相同。这限制了其在机器翻译等任务中的应用,因为这些任务通常需要将不同长度的源语言序列转换为目标语言序列。序列到序列模型 (Sequence to Sequence, Seq2Seq) 通过编码器-解码器架构解决了这些问题,它允许输入和输出序列具有不同的长度,特别适用于机器翻译、文本摘要等任务。
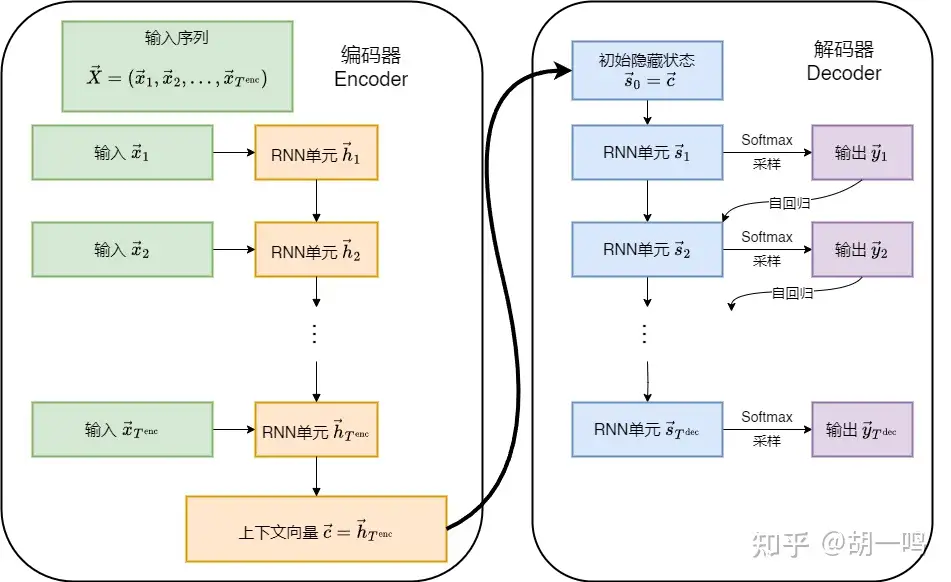
3.1 编码器
给定输入序列 X→=(x→1,x→2,…,x→Tenc) ,其中 x→t∈Rd 表示第 t 个时间步的输入向量, d 为输入特征维度, Tenc 为输入序列长度。编码器 (Encoder) 将整个输入序列编码为固定维度的上下文向量 c→∈Rdh ,其中 dh 为隐藏状态维度(为简化表示,编码器和解码器使用相同的隐藏状态维度,实际中可以不同)。编码器在每个时间步 t 计算隐藏状态 h→t :
输入序列: \vec{X} = (\vec{x}_1, \vec{x}_2, ..., \vec{x}_{T^{\text{enc}}}), 其中 \vec{x}_t \in \mathbb{R}^dh→t=σ(Wh,ench→t−1+Wx,encx→t+b→h,enc)
\vec{h}_t = \sigma(W^{h, \text{enc}} \vec{h}_{t-1} + W^{x, \text{enc}} \vec{x}_t + \vec{b}^{h, \text{enc}}) \vec{h}_t = \sigma(W^{h, \text{enc}} \vec{h}_{t-1} + W^{x, \text{enc}} \vec{x}_t + \vec{b}^{h, \text{enc}}) W^{h, \text{enc}} \in \mathbb{R}^{d_h \times d_h}, 为编码器隐藏状态权重矩阵, W^{x, \text{enc}} \in \mathbb{R}^{d_h \times d} , 为编码器输入权重矩阵, \vec{b}^{h, \text{enc}} \in \mathbb{R}^{d_h}, 为编码器偏置项, 其中 Wh,enc∈Rdh×dh 为编码器隐藏状态权重矩阵, Wx,enc∈Rdh×d 为编码器输入权重矩阵, b→h,enc∈Rdh 为编码器偏置项, σ 为激活函数(通常为tanh或ReLU)。编码过程可以表示为:
c→=fenc(X→)=h→Tenc
\vec{c} = f_{\text{enc}}(\vec{X}) = \vec{h}_{T^{\text{enc}}} \vec{c} = f_{\text{enc}}(\vec{X}) = \vec{h}_{T^{\text{enc}}} 其中 fenc 表示编码器把词向量的序列转化为上下文向量的过程。在这里,最简单的选择是,把 RNN 读取完整个输入句子的最后一个隐藏状态 h→Tenc 作为上下文向量 c→ 。这基本上就要求 RNN 在阅读句子的过程中,能在隐藏状态里记住整个句子的信息。
3.2 解码器
读完句子之后,就轮到解码器 (Decoder) 干活了,它开始一个词一个词地进行生成。我们用 τ 表示解码器的时间步,以区别于编码器的时间步 t 。解码器根据上下文向量 c→ 生成输出序列 Y→=(y→1,y→2,…,y→Tdec) ,其中 y→τ∈RN 表示第 τ 个时间步的输出向量, N 为输出特征维度, Tdec 为输出序列长度。和一般的 RNN 一样,对于机器翻译这类生成字符的应用而言,输出的 y→τ 就是词表中各个词元的概率分数,通过 softmax 函数即可直接转换为概率。
在每个输出的时间步 τ ,解码器根据前一时刻的输出 y→τ−1 、隐藏状态 s→τ−1 以及上下文向量 c→ 计算当前输出:
y→τ=fdec(y→τ−1,s→τ−1,c→)
\vec{y}_{\tau} = f_{\text{dec}}(\vec{y}_{\tau-1}, \vec{s}_{\tau-1}, \vec{c}) \vec{y}_{\tau} = f_{\text{dec}}(\vec{y}_{\tau-1}, \vec{s}_{\tau-1}, \vec{c}) 解码器的隐藏状态 s→τ 则和一般的 RNN 一样,由前一个 s→τ−1 转移而来。只不过需要多加一个上下文向量 c→ ,以及还要读取上一个输出的字符 y→τ−1 :
s→τ=σ(Ws,decs→τ−1+Wy,decy→τ−1+Wc,decc→+b→s,dec)
\vec{s}_{\tau} = \sigma(W^{s, \text{dec}} \vec{s}_{\tau-1} + W^{y, \text{dec}} \vec{y}_{\tau-1} + W^{c, \text{dec}} \vec{c} + \vec{b}^{s, \text{dec}}) \vec{s}_{\tau} = \sigma(W^{s, \text{dec}} \vec{s}_{\tau-1} + W^{y, \text{dec}} \vec{y}_{\tau-1} + W^{c, \text{dec}} \vec{c} + \vec{b}^{s, \text{dec}}) 其中 Ws,dec 为解码器隐藏状态权重矩阵, Wy,dec 为解码器输出权重矩阵, Wc,dec 为解码器上下文权重矩阵, b→s,dec 为解码器偏置项, σ 为激活函数。这种计算方式使得解码器能够同时考虑前一时刻的隐藏状态、输出以及上下文信息,从而更好地生成当前时刻的输出。
注意,量 y→τ−1 严格来说表示的是前一时刻输出词元的概率分布,但是我们这里直接用它来表示已经根据概率分布采样完毕的、确定了是哪一个词元的输出。这种需要把已经输出的内容,重新输入回神经网络的行为,叫做自回归生成(Auto-regressive Generation)。
4 Bahdanau 注意力机制
传统的Seq2Seq模型将整个输入序列编码为固定长度的上下文向量 c→ ,这在处理长序列时存在信息瓶颈问题。特别是当输入序列较长时,RNN难以将所有相关信息压缩到单个向量中,导致模型性能下降。
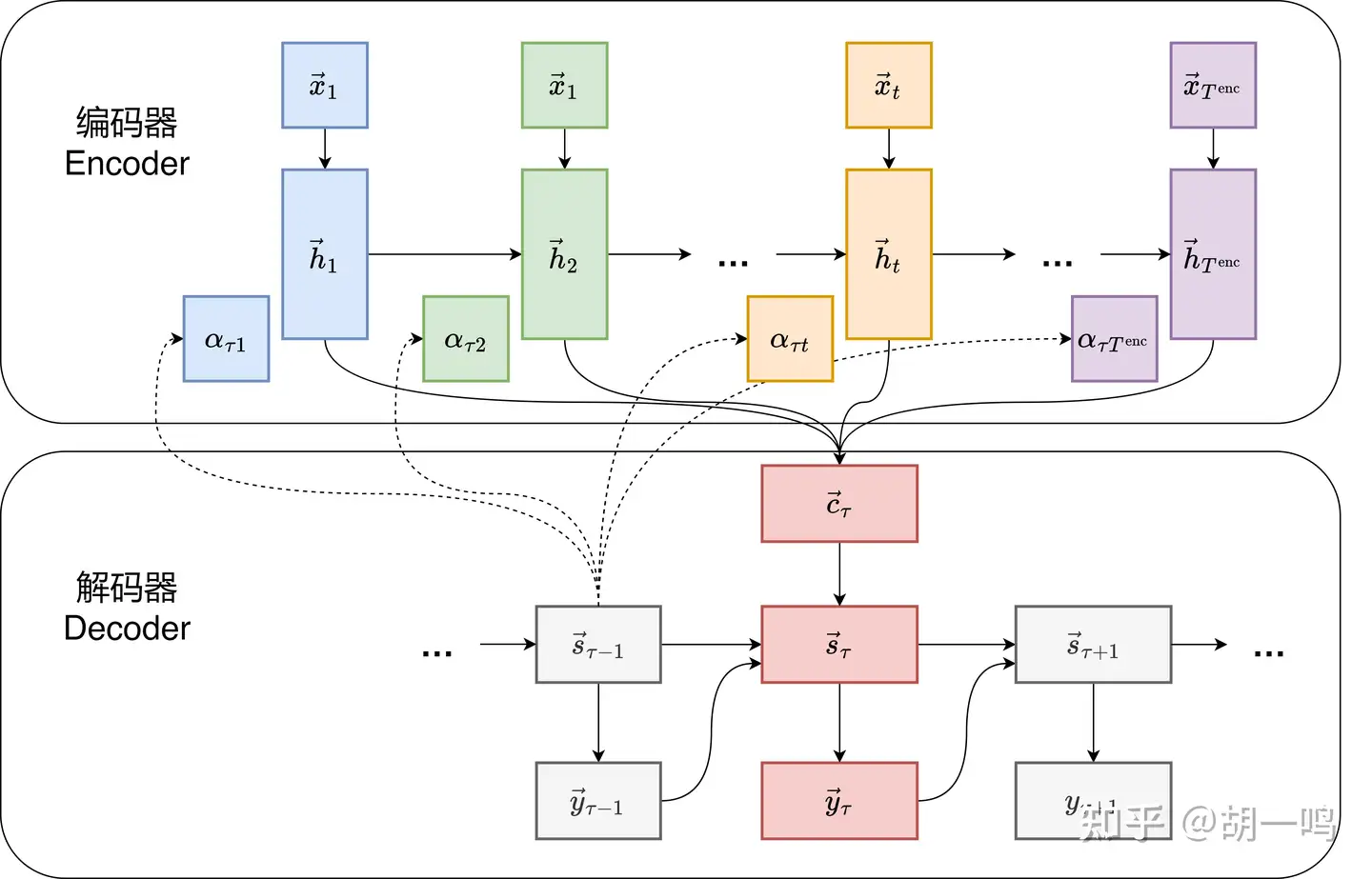
Bahdanau 等人引入的注意力机制 (Attention Mechanism),通过为每个解码时间步 τ 动态生成不同的上下文向量 c→τ 来解决这一问题。具体来说,在生成每个输出 y→τ 时,解码器会关注输入序列的不同部分,而不是使用固定的上下文向量。这种关注程度通过注意力权重 ατt 来表示,即在生成第 τ 个输出时对第 t 个输入编码状态的关注程度。
换句话说,注意力机制的重点,就是对输入进行加权平均。在传统 Seq2Seq 中,要求把所有输入句子的内容,记在一个有限维度的上下文向量 c→ 中,但凡句子稍微长一点,就肯定会出问题——你很难想象一个 2000 维度的上下文向量能表示一篇 1000 字长的文章。那如果在每一步解码的时候,能有办法把所有输入步所对应的隐藏状态 h→t 利用起来,这样对神经网络的要求就降低了很多,它只需要确保 t 步的隐藏状态 h→t 能表示它周围局部的语义即可。
所以现在我们明确了,需要用编码器的所有隐藏状态 {h→t}t=1Tenc 来作为解码器的输入,代替原有的、只用最后一个隐藏状态的上下文向量 c→=h→Tenc 。那么,下一个问题就是,怎么替换呢?
用一堆向量来表示一个向量,最简单的做法就是用线性表示,即
c→τattn=∑t=1Tencατth→t
\vec{c}_{\tau}^{\text{attn}} = \sum_{t=1}^{T^{\text{enc}}} \alpha_{\tau t} \vec{h}_t \vec{c}_{\tau}^{\text{attn}} = \sum_{t=1}^{T^{\text{enc}}} \alpha_{\tau t} \vec{h}_t 其中 ατt 就是线性表示引入的不同的线性系数。这样不同隐藏状态的影响就有大有小,很符合直觉。输入文本中有些字,和当前我们想要输出的字没什么关系;而另一些字则关系密切,在翻译的时候必须考虑。
但是,输入句子的长度 Tenc 是没法固定的 (不然这也太不优雅了,把循环神经网络的好处都扔掉了),所以线性系数 ατt 不能直接用神经网络的参数 (因为参数的数目在训练的时候就已经定死了)。
既然如此,这个系数就应当是一个和 t 以及 τ 都有关的、动态的量。什么量会由时间步决定?那自然就是编码器和解码器的隐藏状态, h→t以及s→τ−1 了。这里用了 τ−1 ,是因为我们还没计算出来 s→τ 呢。当然,也可以考虑直接用词元 x→t 和 y→τ−1 ,但这样总归是丢失了”词在句子中的语义”,而只剩下”词本身的语义”了。注意我们这里为了避免引入过多变量,混淆了输入词元和词向量,以及输出词元分布、词元和词向量。
于是现在,我们要用两个隐藏状态向量,来计算一个数字,作为线性表示的系数,或者说注意力权重。那此时就可以用神经网络的参数来计算啦,毕竟隐藏状态向量的维度是固定的。所以注意力权重通过以下方式计算:
ατt=exp(eτt)∑k=1Tencexp(eτk)
\alpha_{\tau t} = \dfrac{\exp(e_{\tau t})}{\sum_{k=1}^{T^{\text{enc}}} \exp(e_{\tau k})}\alpha_{\tau t} = \dfrac{\exp(e_{\tau t})}{\sum_{k=1}^{T^{\text{enc}}} \exp(e_{\tau k})}并且
eτt=v→attn⋅tanh(Ws,attns→τ−1+Wh,attnh→t+b→attn)
e_{\tau t} = {\vec{v}^{\text{attn}}} \cdot \tanh(W^{s, \text{attn}} \vec{s}_{\tau-1} + W^{h, \text{attn}} \vec{h}_t + \vec{b}^{\text{attn}})e_{\tau t} = {\vec{v}^{\text{attn}}} \cdot \tanh(W^{s, \text{attn}} \vec{s}_{\tau-1} + W^{h, \text{attn}} \vec{h}_t + \vec{b}^{\text{attn}})其中 Ws,attn 和 Wh,attn 为注意力机制中的神经网络参数矩阵, v→attn 为注意力机制中的参数列向量, b→attn 为注意力机制的偏置项。这里除了用神经网络来计算注意力权重之外,还要加一个 softmax 归一化,这样所有注意力权重的和就是 1 了。
解码器在生成每个输出、更新隐藏状态时,就使用 c→τattn 这个动态上下文向量,来替换原有的上下文向量 c→ :
s→τ=σ(Ws,decs→τ−1+Wy,decy→τ−1+Wc,decc→τ+b→s,dec)
\vec{s}_{\tau} = \sigma(W^{s, \text{dec}} \vec{s}_{\tau-1} + W^{y, \text{dec}} \vec{y}_{\tau-1} + W^{c, \text{dec}} \vec{c}_{\tau} + \vec{b}^{s, \text{dec}}) \vec{s}_{\tau} = \sigma(W^{s, \text{dec}} \vec{s}_{\tau-1} + W^{y, \text{dec}} \vec{y}_{\tau-1} + W^{c, \text{dec}} \vec{c}_{\tau} + \vec{b}^{s, \text{dec}}) 其中 Ws,dec 、 Wy,dec 和 Wc,dec 为解码器的参数矩阵, b→s,dec 为解码器的偏置项。这种机制允许模型在处理长序列时更有效地利用输入信息,显著提高了Seq2Seq模型在机器翻译等任务中的性能。
5 Transformer
只有在理解了 RNN 、Seq2Seq 以及为何需要在 Seq2Seq 中引入注意力机制之后,才能理解,为什么 Transformer 的论文要取名为 Attention is all you need,以及作者们在论文标题中,暗示我们用注意力机制取代的那种东西,到底是什么?当然,或许可以猜到他们想要干掉 RNN。所以为什么要干掉 RNN ?
在这里,我们对上一节介绍用 RNN 进行自然语言处理的发展脉络,尤其是每提出一种结构所解决的问题以及引入的新问题,做一个回顾。
| 模型/技术 | 核心结构 | 优势 | 问题 |
|---|---|---|---|
| 基础RNN | 循环隐藏状态 | 处理变长序列 | 输出与输入长度一致 |
| Seq2Seq | 编码器-解码器架构 | 输入输出长度解耦 | 上下文向量成为信息瓶颈 |
| 注意力机制 | 动态上下文向量 | 长程依赖捕捉 | 前后依赖关系, 难以并行 |
| Transformer | 自注意力机制 | 完全并行计算 | 上下文平方增长计算量 |
5.1 自注意力机制
Transformer 的核心是自注意力机制,它是这种新架构能超越RNN的关键,因而它的思想值得细细体会。
5.1.1 自注意力机制的思想
如果说,原始的注意力机制是让解码器在输出时,能够得以关注编码器在处理输入时的信息。那么,如果把这种机制,用在加强文本自身的表述能力上,就形成了自注意力机制。这是 Transformer 最核心的模块,所以我们最先讨论其原理和思想,随后再依次介绍详细的架构。
考虑这样的叙事:
在一段文本中,某个词元的真正语义,有可能要等到后续的所有内容出现了之后,才能完全确定。
这种情况在英语中尤其常见,比如各种各样的从句,而在汉语中也常常会遇到这种情况。当然,还有的时候哪怕文本读完了都不能确定语义,但这一般就是病句或者碰到谜语人了。现在我们的目标是让模型能翻译一般的句子,解读谜语人有点太强模型所难了,我们暂且忽略这种情况。
那么 RNN 就有点难以处理这种情况。RNN 在读取文字的时候,必须顺序读取,并且隐藏状态 h→t 只由已经读过的词元决定。这意味着,RNN 如果在读到某个词元时感到困惑了,那么它就不得不将这份困惑所对应的隐藏状态留在原地;而在后面的内容也读完、能确定这个词元的语义时,才能在隐藏状态中默默地把词元的语义给更新一下。当然对于 RNN 来说,更新已经读取的词元的语义并不是完全做不到的,只是确实不那么简单。
那有没有更加直观、有效的方式,能够直接表示出”词元在句子中的语义”?自注意力机制,就是这种能够完整利用整个句子的所有信息,来表达”某个词元的在句子中语义”的结构。
给定输入序列 X→=(x→1,x→2,…,x→T) ,其中 x→t∈Rd 表示第 t 个时间步的输入向量 (默认是列向量), d 为输入特征维度, T 为输入序列长度。下面的推导都很不严谨,不过我们不要在意这些,更多的是希望能马后炮地探究一下,自注意力机制的形式为什么是论文中呈现的样子。我们用 d 维列向量 z→t 表示”第 t 个词元在句子中的语义”这件事,那么其”语义应由句子中的所有词元共同决定”这件事,可以视作:
z→t=f(x→1,x→2,…,x→t,x→t+1,…,x→T)
\vec{z}_{t} = f(\vec{x}_1, \vec{x}_2, ..., \vec{x}_{t}, \vec{x}_{t+1}, ..., \vec{x}_{T}) \vec{z}_{t} = f(\vec{x}_1, \vec{x}_2, ..., \vec{x}_{t}, \vec{x}_{t+1}, ..., \vec{x}_{T}) 也就是所有这些向量的函数。用一堆向量映射到同样维度的另一个向量,最简单的映射方法当然是线性表示:
z→t=∑i=1Tαtix→i
\vec{z}_{t} = \sum_{i=1}^{T} \alpha_{t i} \vec{x}_{i} \vec{z}_{t} = \sum_{i=1}^{T} \alpha_{t i} \vec{x}_{i} 这样这个式子就有点注意力机制那种在序列中加权求和的思路了。
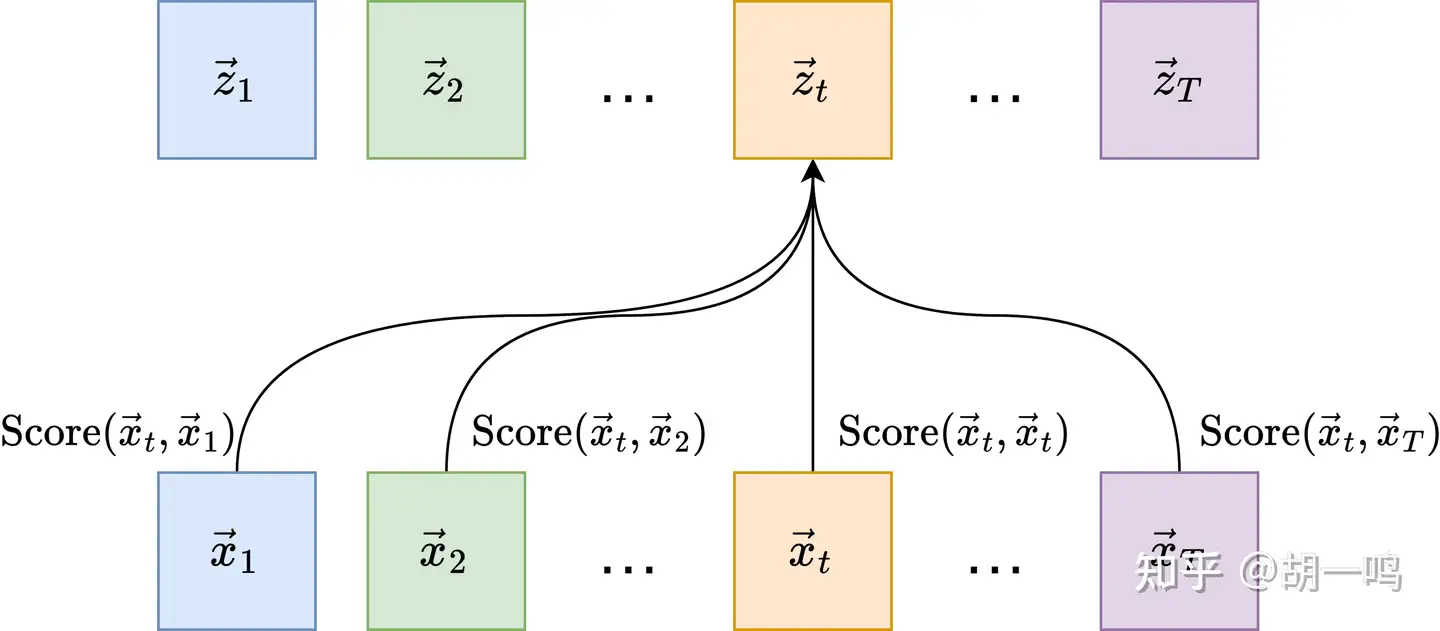
不过,这个形式的有效性可能会有点问题:线性表示是和基底向量排列的顺序无关的。也就是说理论上如果我把两个词元交换一下位置,其结果并不会改变。这显然不符合自然语言的情况!不过我们先放下这个问题,后面我们会看到实际上进行这一步计算的向量中本身是带了顺序信息的,方法是位置编码。这里,我们只需要知道这里的确考虑了顺序信息,而依然使用线性表示即可。
现在我们来确定系数的形式,和原始的注意力机制一样,因为序列是不定长的,所以不能直接拿模型参数作为系数。不过,假如说,我们考虑某个句子,其每个词元的单独的语义都和句子里的其他词元没什么关系,它们是正交的。那么此时,系数就可以用向量分解表示了,并且系数就是内积:
z→t∼x→t=∑i=1T(x→t⋅x→i)x→i
\vec{z}_{t} \sim \vec{x}_t = \sum_{i=1}^{T} (\vec{x}_t \cdot \vec{x}_i) \vec{x}_{i} \vec{z}_{t} \sim \vec{x}_t = \sum_{i=1}^{T} (\vec{x}_t \cdot \vec{x}_i) \vec{x}_{i} 这个式子当然不是 Self-Attention 的正确形式,它只是一个平凡的向量展开式而已,而且在大多数情况下都不满足正交性的先决条件。但我们至少可以从它的数学结构 (特别要关注下角标) 中窥探到一些信息:线性组合的系数由当前词元 z→t 与其他词元 x→i,i=1,2,⋯,T 的某个函数 f(x→t,x→i) 决定。
那么具体这个函数是什么呢?我们可以考虑一下三个量的地位:
- 系数中的 x→t ,表示的是当前词元。有点像”试探者”的感觉,如果你学过大学物理,那么这有点像测试电荷的地位。我们姑且把它比作数据库中的”查询”,也就是 Query。尽管我觉得这个比喻比较牵强,但 Transformer 原作者愿意使用这个比喻,并且以此给相关的向量或者矩阵来命名。
- 系数中的 x→i ,表示的是其他词元。有点像在大学物理中,有点像被测试的电荷分布的感觉。在数据库的比喻中,这是”键”,也就是 Key。
- 作为正交基底的 x→i ,表示的是组成词语在句子中的语义的基底。有点像在大学物理中,得到的各个电荷各自的电场力的感觉。在数据库的比喻中,这是”值”,也就是 Value。
既然三者地位不同,而对应矢量的值直接表示语义,那么现在这些矢量也不能直接用词向量 x→ 了。应该用什么,把孤立的词向量的语义,转化为在句子中具有对应地位的语义呢?一个简单的想法是,直接作线性变换:
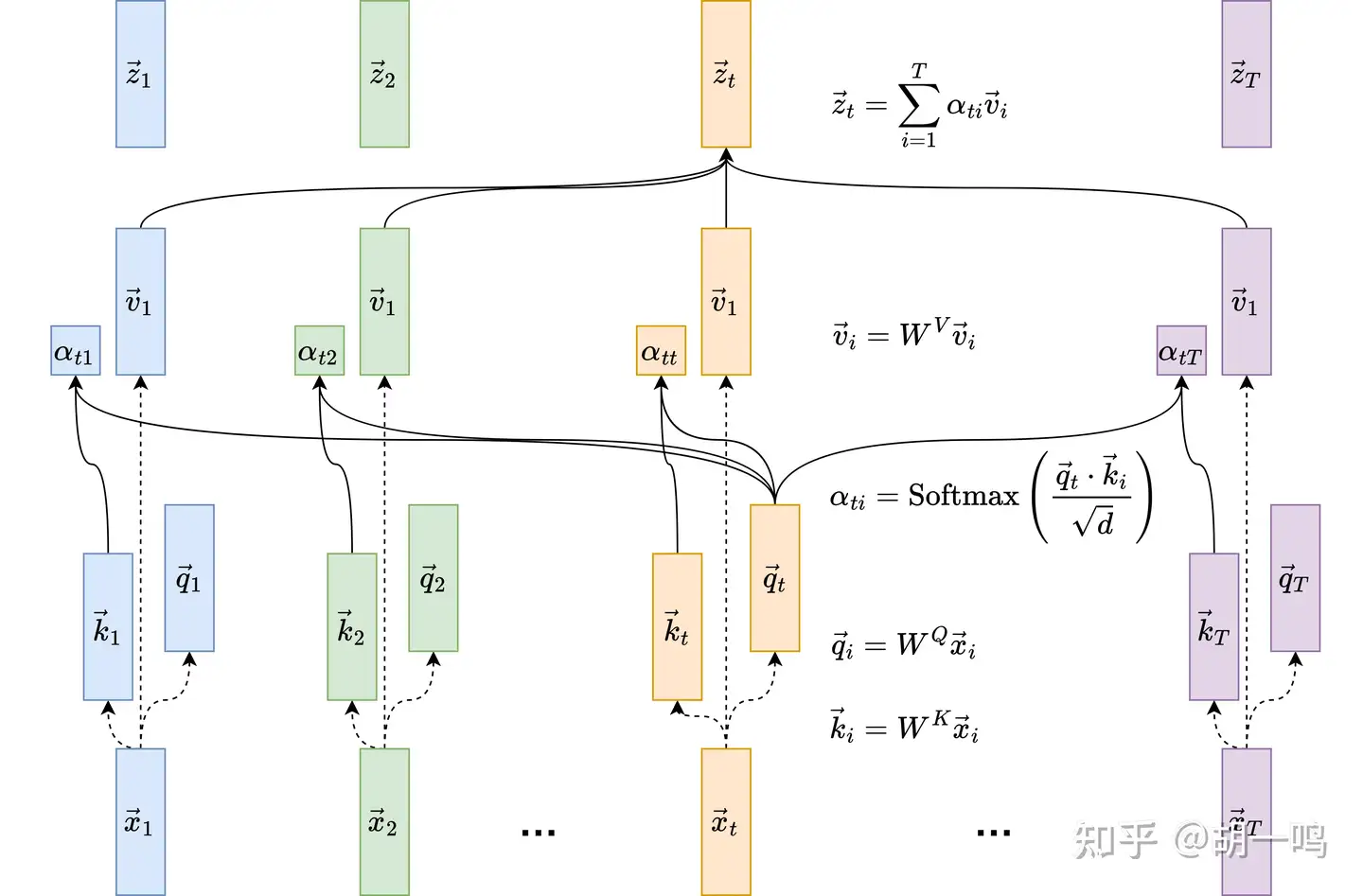
q→t=WQx→t,k→t=WKx→t,v→t=WVx→t
\vec{q}_t = W^{Q}\vec{x}_t,\quad \vec{k}_t = W^{K}\vec{x}_t,\quad \vec{v}_t = W^{V}\vec{x}_t \vec{q}_t = W^{Q}\vec{x}_t,\quad \vec{k}_t = W^{K}\vec{x}_t,\quad \vec{v}_t = W^{V}\vec{x}_t 就搞定了。我们可以期待,这种把孤立语义,转化为具有在计算中的特定地位语义的行为,是相对固定的,也就是说,三个矩阵 WQ,WK,WV 可以是模型参数。
现在用变换后的三个向量去替换那个平凡的向量展开式,得到
z→t=∑i=1Tα(q→t,k→i)v→i
\vec{z}_t = \sum_{i=1}^{T} \alpha(\vec{q}_t, \vec{k}_i) \vec{v}_{i} \vec{z}_t = \sum_{i=1}^{T} \alpha(\vec{q}_t, \vec{k}_i) \vec{v}_{i} 那么系数 α(q→t,k→i) 是什么形式呢?和上面一样,就还是作点积,只是加一个 softmax 进行一下归一化而已:
α(q→t,k→i)=Softmax(q→t⋅k→i/d)=exp(q→t⋅k→i/d)∑j=1Texp(q→t⋅k→j/d)
\alpha(\vec{q}_t, \vec{k}_i) = \text{Softmax}\left( \vec{q}_t \cdot \vec{k}_i / \sqrt{d} \right) = \dfrac{ \exp \left(\vec{q}_t \cdot \vec{k}_i / \sqrt{d}\right) }{ \sum_{j=1}^{T}\exp\left(\vec{q}_t \cdot \vec{k}_j / \sqrt{d}\right) } \alpha(\vec{q}_t, \vec{k}_i) = \text{Softmax}\left( \vec{q}_t \cdot \vec{k}_i / \sqrt{d} \right) = \dfrac{ \exp \left(\vec{q}_t \cdot \vec{k}_i / \sqrt{d}\right) }{ \sum_{j=1}^{T}\exp\left(\vec{q}_t \cdot \vec{k}_j / \sqrt{d}\right) }这里我们给点积还加了一个 1/d 的因子,主要是希望词向量的维度比较大的时候,数值稳定性能好一点。另外,尽管这里加 softmax 看上去好像仅仅只是一个平凡的归一化操作,但它的实际作用是非常大的。后面会更详细地讨论这些细节。
现在,我们将序列中的所有向量拼接成矩阵形式。令输入序列的矩阵表示为 X=[x→1,⋯,x→T]∈Rd×T ,其中每个 x→t 是 d 维的列向量。类似地,我们可以定义:
- 查询矩阵 Q=WQX∈Rd×T ,其中 WQ∈Rd×d 是查询对应的模型参数矩阵
- 键矩阵 K=WKX∈Rd×T ,其中 WK∈Rd×d 是键对应的模型参数矩阵
- 值矩阵 V=WVX∈Rd×T ,其中 WV∈Rd×d 是值对应的模型参数矩阵
查询矩阵: Q = W^Q X \in \mathbb{R}^{d \times T} ,W^Q \in \mathbb{R}^{d \times d}键矩阵 :K = W^K X \in \mathbb{R}^{d \times T},W^K \in \mathbb{R}^{d \times d}值矩阵 :V = W^V X \in \mathbb{R}^{d \times T}, W^V \in \mathbb{R}^{d \times d}则自注意力机制可以表示为矩阵运算:
Z=[Softmax(Q⊤Kd)]⊤V
Z = \left[ \text{Softmax}\left( \frac{Q^\top K}{\sqrt{d}} \right) \right]^\top V Z = \left[ \text{Softmax}\left( \frac{Q^\top K}{\sqrt{d}} \right) \right]^\top V 其中 Z∈Rd×T 是自注意力层的输出矩阵, Softmax 函数按列进行归一化。这里的形式与原始 Transformer 论文中的形式略有不同,主要是因为我们将输入向量定义为列向量,而原论文中采用的是行向量的定义方式。两种定义在数学上是等价的,只是矩阵的转置位置有所不同。
现在,我们分析自注意力机制的计算复杂度。对于输入序列长度为 T 的情况,计算主要包含以下几个步骤:
- 计算 Q,K,V 矩阵的复杂度为 O(d2T) ,其中 d 是向量维度;
- 计算注意力分数矩阵 Q⊤K 的复杂度为 O(dT2) ;
- 计算 softmax 归一化的复杂度为 O(T2) ;
- 计算加权和 AV 的复杂度为 O(dT2) 。
其中,后三个步骤的复杂度都与 T2 成正比,因此自注意力机制的整体计算复杂度为 O(T2) ,即随着输入上下文长度的平方增长。
这种平方增长的计算复杂度具有双重意义:
一方面,每个词元都需要与序列中所有其他词元进行交互计算,这保证了每个字的语义以及字与字之间的关联都能被充分理解和捕捉,这种全局的注意力机制是 Transformer 模型效果强大的重要保障;
另一方面,随着输入序列长度的增加,计算量会快速膨胀,这限制了 Transformer 模型能够处理的输入序列长度。我们和大模型聊天的时候,聊着聊着就发现大模型忘记了前面的内容,原因正在于此。
5.1.2 位置编码
实际上,在自注意力机制的思想中,可能会注意到一个问题。当时,我们说”词元在句子中的语义”,需要由整个句子中的所有词元共同决定。我们使用了线性表示的公式,来表示这件事情。
但是,线性表示是与顺序无关的。也就是说,如果交换了两个词元的顺序,那么计算结果并不会变化。这显然不是自然语言中的情况,哪种语言能随意交换词的顺序,而绝不会改变语义呢?如果我们还想保留线性表示的思想,那就需要让那些表示语义的向量包含能够表示位置的信息。
所幸,确实有办法能给词向量添加位置信息,这种方法就叫做位置编码 (Positional Encoding)。对于第 t 个词向量 O(T2) ,其经过位置编码之后的向量可以写为
x→~t=x→t+p→t
\tilde{\vec{x}}_t = \vec{x}_t + \vec{p}_t \tilde{\vec{x}}_t = \vec{x}_t + \vec{p}_t 其中 p→t 就是第 t 个位置的位置编码,它只和其在输入序列中的位置,也就是 t 有关。在 Transformer 论文中,位置编码向量是
p→t=[sin(t/100000/d)cos(t/100000/d)sin(t/100002/d)cos(t/100002/d)⋮sin(t/10000(d−2)/d)cos(t/10000(d−2)/d)]
其中 d 是词向量的维度, t 是词在序列中的位置。
\vec{p}_t = \begin{bmatrix} \sin(t/10000^{0/d}) \\ \cos(t/10000^{0/d}) \\ \sin(t/10000^{2/d}) \\ \cos(t/10000^{2/d}) \\ \vdots \\ \sin(t/10000^{(d-2)/d}) \\ \cos(t/10000^{(d-2)/d}) \end{bmatrix} \vec{p}_t = \begin{bmatrix} \sin(t/10000^{0/d}) \\ \cos(t/10000^{0/d}) \\ \sin(t/10000^{2/d}) \\ \cos(t/10000^{2/d}) \\ \vdots \\ \sin(t/10000^{(d-2)/d}) \\ \cos(t/10000^{(d-2)/d}) \end{bmatrix} 位置编码初看上去还是相当奇怪的:这里和三角函数怎么扯上了关系?而且每个分量的频率还不太一样。这真的能把位置信息给弄进词向量吗?这真的不会破坏掉词向量原本的信息吗?
在这里提供一些唯象的、不严格的分析。
首先,我们考虑位置编码会不会抹掉词向量原本的信息。如果词向量是一个一维的实数 xt ,那么让它与另一个实数 pt 相加,的确就会抹掉原本的信息。但现在词向量 x→t 是一个维度很高的向量,而不是一个实数。不论与词向量 x→t 相加的位置编码 p→t 是什么,它都可以比较容易地被归结为某个子空间内的相加,从而在另一些子空间内保留了原本的信息。尽管这种子空间可能是非线性的,但它只和位置有关,仍很容易被神经网络学到。
然后,为什么是三角函数?我们能隐约感觉到,三角函数和旋转、周期性、循环群之类的概念有关。而旋转这件事天然就更加关注相对位置,而非绝对位置。为了说明这点,我们来计算两个词向量之间的内积:
孤立词向量之间的关系词向量与位置之间的关系相对位置关系q→t1⋅k→t2=WQ(x→t1+p→t1)⋅WK(x→t2+p→t2)=WQx→t1⋅WKx→t2⏟孤立词向量之间的关系+WQx→t1⋅WKp→t2+WQp→t1⋅WKx→t2⏟词向量与位置之间的关系+WQp→t1⋅WKp→t2⏟相对位置关系
\begin{aligned} \vec{q}_{t_1} \cdot \vec{k}_{t_2} =& W^{Q}(\vec{x}_{t_1} + \vec{p}_{t_1}) \cdot W^{K}(\vec{x}_{t_2} + \vec{p}_{t_2}) \\ =& \underbrace{W^{Q}\vec{x}_{t_1} \cdot W^{K}\vec{x}_{t_2}}_{\text{孤立词向量之间的关系}} + \underbrace{W^{Q}\vec{x}_{t_1} \cdot W^{K}\vec{p}_{t_2} + W^{Q}\vec{p}_{t_1} \cdot W^{K}\vec{x}_{t_2}}_{\text{词向量与位置之间的关系}} + \underbrace{W^{Q}\vec{p}_{t_1} \cdot W^{K}\vec{p}_{t_2}}_{\text{相对位置关系}} \\ \end{aligned} \begin{aligned} \vec{q}_{t_1} \cdot \vec{k}_{t_2} =& W^{Q}(\vec{x}_{t_1} + \vec{p}_{t_1}) \cdot W^{K}(\vec{x}_{t_2} + \vec{p}_{t_2}) \\ =& \underbrace{W^{Q}\vec{x}_{t_1} \cdot W^{K}\vec{x}_{t_2}}_{\text{孤立词向量之间的关系}} + \underbrace{W^{Q}\vec{x}_{t_1} \cdot W^{K}\vec{p}_{t_2} + W^{Q}\vec{p}_{t_1} \cdot W^{K}\vec{x}_{t_2}}_{\text{词向量与位置之间的关系}} + \underbrace{W^{Q}\vec{p}_{t_1} \cdot W^{K}\vec{p}_{t_2}}_{\text{相对位置关系}} \\ \end{aligned} 特别是,对于位置与位置之间的内积,利用余弦和的公式,把奇偶的分量合并计算,我们有
p→t1⋅p→t2=∑k=0d/2−1cos(wk(t1−t2)),wk=1100002k/d
\vec{p}_{t_1} \cdot \vec{p}_{t_2} = \sum_{k=0}^{d/2-1} \cos\left( w_k (t_1 - t_2) \right),\quad w_k = \frac{1}{10000^{2k/d}} \vec{p}_{t_1} \cdot \vec{p}_{t_2} = \sum_{k=0}^{d/2-1} \cos\left( w_k (t_1 - t_2) \right),\quad w_k = \frac{1}{10000^{2k/d}} 这意味着,任意两个具有不同距离的位置编码向量之间的内积,都不太一样,这种位置编码适合用来区分不同词元之间的相对位置。这就很契合自然语言的需求了:当我们在句子前加一些没有意义的空格,我们当然希望位置编码可以不要过多地改变词向量的语义。
每个分量的频率不一样的话,就更有利于在不同尺度上考虑词元与词元的关系了。最上面那几个分量频率很高,就更加适合关注句子内部相邻两个词之间的关系;最下面的分量频率很低,则更加适合表征大范围的语义关系,从而在长上下文中非常有用。
当然也存在一些其他的位置编码选择,例如 RoPE、ALiBi 等,大多数方案都会着重表征相对位置而弱化绝对位置。例如,RoPE 对旋转的运用比这里要更激进一些,例如直接把旋转矩阵作用到 q→ 和 k→ 向量头上了,这样点乘的时候就会自然地引入角度,而额外的夹角就只和相对位置有关。
5.1.3 多头自注意力机制
在介绍了位置编码之后,我们即可对多头自注意力部分进行严格定义。这里我们首先考虑编码器中,第一层的多头注意力 (Multi-Head Attention, MHA) 机制。堆叠之后的多头注意力机制和这里的区别,仅仅只是输入向量从经过位置编码的词向量,变为由前面的层所输出的那些向量而已。
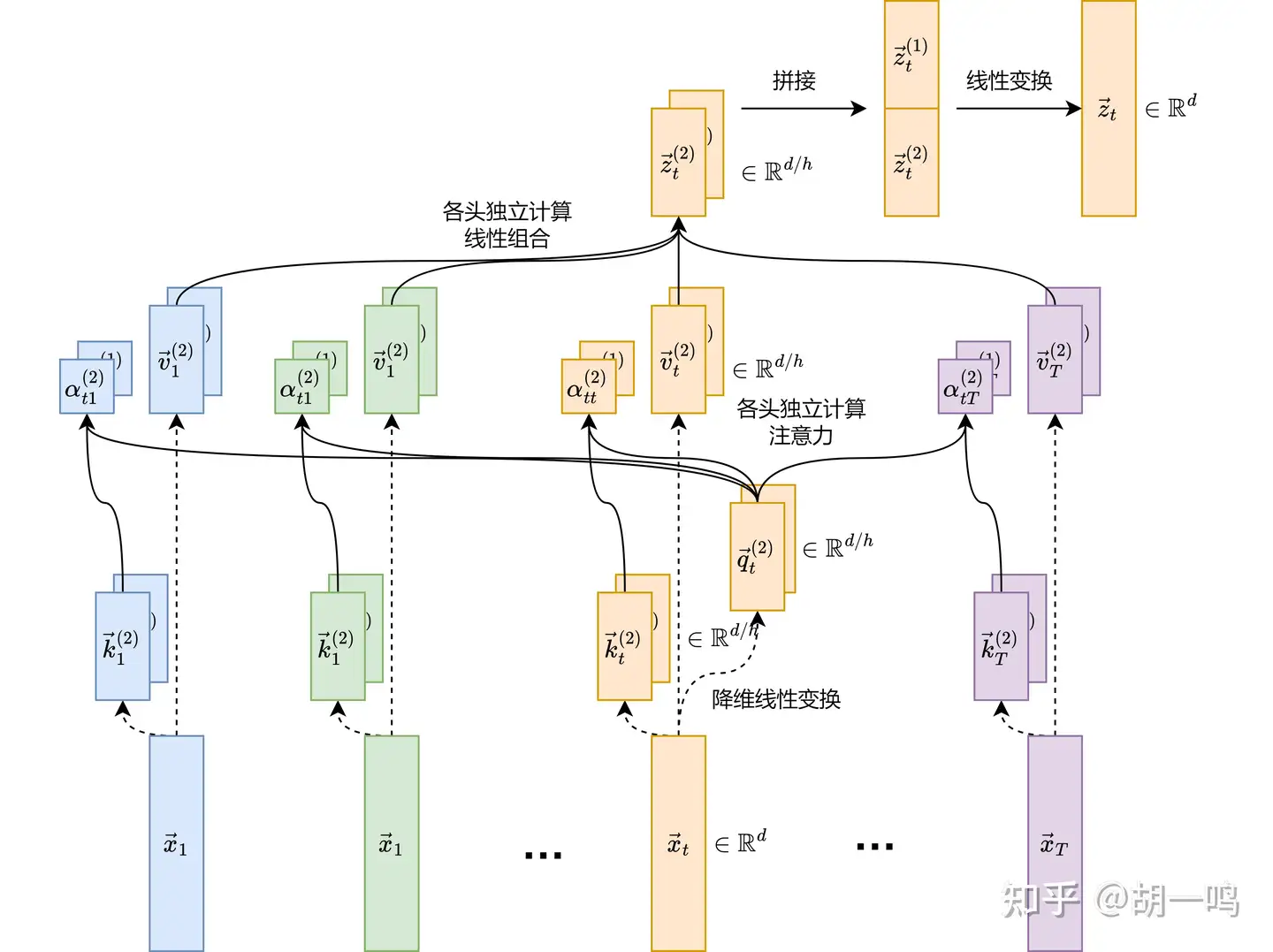
接下来考虑什么是”多头”。设 h 是头的数目,一般是向量维度 d 的整数因子。这样,向量 q→t 就可以被分成为 h 个长度为 dh 的子向量,其中每个子向量记作 q→t(j)∈Rd/h ,其中 j=1,2,⋯,h 。接下来,根据自注意力机制的手续,我们对输入向量作线性变换:
q→t(j)=WQ(j)x→t,j=1,2,⋯,hk→t(j)=WK(j)x→t,j=1,2,⋯,hv→t(j)=WV(j)x→t,j=1,2,⋯,h
\begin{aligned} {\vec{q}_t}^{(j)} =& {W^{Q}}^{(j)} \vec{x}_{t},\quad j=1,2,\cdots,h \\ {\vec{k}_t}^{(j)} =& {W^{K}}^{(j)} \vec{x}_{t},\quad j=1,2,\cdots,h \\ {\vec{v}_t}^{(j)} =& {W^{V}}^{(j)} \vec{x}_{t},\quad j=1,2,\cdots,h \end{aligned} \begin{aligned} {\vec{q}_t}^{(j)} =& {W^{Q}}^{(j)} \vec{x}_{t},\quad j=1,2,\cdots,h \\ {\vec{k}_t}^{(j)} =& {W^{K}}^{(j)} \vec{x}_{t},\quad j=1,2,\cdots,h \\ {\vec{v}_t}^{(j)} =& {W^{V}}^{(j)} \vec{x}_{t},\quad j=1,2,\cdots,h \end{aligned} 其中 WQ(j),WK(j),WV(j) 分别是第 j 个头所对应的权重矩阵,维度是 Rdh×d 。相当于是说,每个头都有自己独立的矩阵,把原本的 d 维向量通过线性变换降维成了 d/h 维的子向量。不过这倒不用担心造成信息损失,因为所有头的结果最后会拼接起来的,所以最后仍是 d 维向量。
然后,在某个头内,自注意力的输出子向量是
z→t(j)=∑i=1Tαti(j)v→i(j)
{\vec{z}_{t}}^{(j)} = \sum_{i=1}^{T} \alpha_{ti}^{(j)}{\vec{v}_{i}}^{(j)} {\vec{z}_{t}}^{(j)} = \sum_{i=1}^{T} \alpha_{ti}^{(j)}{\vec{v}_{i}}^{(j)} 其中 αti(j) 是一个注意力权重,也就是线性表示的系数。老朋友了,按照惯例是点积+Softmax:
αti(j)=exp((q→t(j)⋅k→i(j))/d/h)∑k=1Texp((q→t(j)⋅k→k(j))/d/h)
\alpha_{ti}^{(j)} = \dfrac{\exp\left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_i}^{(j)}) / \sqrt{d/h} \right) }{ \sum_{k=1}^{T} \exp \left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_k}^{(j)}) / \sqrt{d/h} \right) } \alpha_{ti}^{(j)} = \dfrac{\exp\left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_i}^{(j)}) / \sqrt{d/h} \right) }{ \sum_{k=1}^{T} \exp \left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_k}^{(j)}) / \sqrt{d/h} \right) } 最后,把所有头的输出子向量拼接起来,再通过一个线性变换,即可得到多头自注意力层的输出向量:
z→t=WO[z→t(1)z→t(2)⋮z→t(h)]
\vec{z}_{t} = W^{O} \begin{bmatrix} {\vec{z}_{t}}^{(1)} \\ {\vec{z}_{t}}^{(2)} \\ \vdots \\ {\vec{z}_{t}}^{(h)} \end{bmatrix} \vec{z}_{t} = W^{O} \begin{bmatrix} {\vec{z}_{t}}^{(1)} \\ {\vec{z}_{t}}^{(2)} \\ \vdots \\ {\vec{z}_{t}}^{(h)} \end{bmatrix} 其中 WO∈Rd×d 是输出权重矩阵。
所以,为什么要多头?八股文的说法是,这种多头机制允许模型在不同的子空间中学习不同的注意力模式,从而捕捉更丰富的语义信息。然后在论文中作者做了消融实验,发现,总参数量相等的情况下,用多头 (权重是 h 个 dh×d 矩阵)确实比单头 (权重是 1 个 d×d 矩阵) 的效果好一点。
但还是很难看出来多头和单头的区别。如果全都是线性变换的话,这样先划分再拼接的操作似乎是不会有什么区别的,毕竟矩阵乘法本来就可以写成分块矩阵乘法再拼接的形式。所以我们这里做一些计算。我们设 d=2 ,然后分别计算 h=1 (单头注意力) 和 h=2 (多头注意力) 两种情况下的最终结果会有什么不同。
- 单头注意力, h=1 。此时,所有计算都在单一子空间中进行。设输入向量为 x→t=[x1,x2]⊤ ,则:
q→t=WQx→t=[w11w12w21w22][x1x2]
\vec{q}_t = W^{Q} \vec{x}_t = \begin{bmatrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} \vec{q}_t = W^{Q} \vec{x}_t = \begin{bmatrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} 类似地计算 k→t 和 v→t 。注意力权重计算为:
αti=exp((q→t⋅k→i)/2)∑k=1Texp((q→t⋅k→k)/2)
\alpha_{ti} = \dfrac{\exp\left( (\vec{q}_t \cdot \vec{k}_i) / \sqrt{2} \right)}{\sum_{k=1}^{T} \exp\left( (\vec{q}_t \cdot \vec{k}_k) / \sqrt{2} \right)} \alpha_{ti} = \dfrac{\exp\left( (\vec{q}_t \cdot \vec{k}_i) / \sqrt{2} \right)}{\sum_{k=1}^{T} \exp\left( (\vec{q}_t \cdot \vec{k}_k) / \sqrt{2} \right)} 最终输出为:
z→t=WO(∑i=1Tαtiv→i)
{\vec{q}_t}^{(j)} = {W^{Q}}^{(j)} \vec{x}_t = \begin{bmatrix} w_{11}^{(j)} & w_{12}^{(j)} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} {\vec{q}_t}^{(j)} = {W^{Q}}^{(j)} \vec{x}_t = \begin{bmatrix} w_{11}^{(j)} & w_{12}^{(j)} \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} - 多头注意力, h=2 。此时,输入向量被分成两个子空间进行处理。设输入向量为 x→t=[x1,x2]⊤ ,则对于每个头 j=1,2 ,我们有:
q→t(j)=WQ(j)x→t=[w11(j)w12(j)][x1x2]
\alpha_{ti}^{(j)} = \dfrac{\exp\left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_i}^{(j)}) / \sqrt{1} \right)}{\sum_{k=1}^{T} \exp\left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_k}^{(j)}) / \sqrt{1} \right)} \alpha_{ti}^{(j)} = \dfrac{\exp\left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_i}^{(j)}) / \sqrt{1} \right)}{\sum_{k=1}^{T} \exp\left( ({\vec{q}_t}^{(j)} \cdot {\vec{k}_k}^{(j)}) / \sqrt{1} \right)} 类似地计算 k→t(j) 和 v→t(j) 。每个头的注意力权重计算为:
αti(j)=exp((q→t(j)⋅k→i(j))/1)∑k=1Texp((q→t(j)⋅k→k(j))/1)
{\vec{z}_{t}}^{(j)} = \sum_{i=1}^{T} \alpha_{ti}^{(j)} {\vec{v}_{i}}^{(j)} {\vec{z}_{t}}^{(j)} = \sum_{i=1}^{T} \alpha_{ti}^{(j)} {\vec{v}_{i}}^{(j)} 每个头的输出为:
z→t(j)=∑i=1Tαti(j)v→i(j)
{\vec{z}_{t}}^{(j)} = \sum_{i=1}^{T} \alpha_{ti}^{(j)} {\vec{v}_{i}}^{(j)} {\vec{z}_{t}}^{(j)} = \sum_{i=1}^{T} \alpha_{ti}^{(j)} {\vec{v}_{i}}^{(j)} 最后将两个头的输出拼接并通过输出矩阵变换:
z→t=WO[z→t(1)z→t(2)]
\vec{z}_t = W^{O} \begin{bmatrix} {\vec{z}_{t}}^{(1)} \\ {\vec{z}_{t}}^{(2)} \end{bmatrix} \vec{z}_t = W^{O} \begin{bmatrix} {\vec{z}_{t}}^{(1)} \\ {\vec{z}_{t}}^{(2)} \end{bmatrix} 这些式子还是很抽象,不过我们如果观察一下注意力权重 α 的角标,立刻就可以发现,在单头注意力中,总共只有 t 和 i 两个角标,意味着有 T2 个注意力权重;而在多头注意力中,则有 t 、 i 和 j 三个角标,意味着有 h×T2 个注意力权重。有多少个头,注意力权重就会多多少倍。
那么是什么造成了多头注意力的权重数目更多呢?的确,之前说过,如果一切都是线性变换, αti=q→t⋅k→i ,那么这些把戏不过是把矩阵乘法变成了分块矩阵的乘法。在最后一步的拼接、左乘 WO 的过程中都会无效的 (因为这一步会把相关的 α 加起来)。
但是 α 不是通过线性变换求出来的,而是通过 Softmax 求出来的。这是一个非线性的变换,于是其效果就和单头注意力的效果大不相同了, h×T2 个注意力权重全都是有用的!它真的可以像八股文中讲的那样让 Transformer 关注到不同的特性。
由此可以看出,Softmax 函数并不是白加的。它有着更加重要的作用。
5.1.4 注意力权重中的 Softmax 函数
在多头注意力机制中,我们看到了在计算注意力权重 αti 时 Softmax 所发挥的作用:提供非线性。现在我们直接看看,如果没有 Softmax 会发生什么:
z→t=∑i=1nαtiv→i=∑i=1n(q→t⋅k→i)v→i
我们令 Z=[z→1,z→2,…,z→T] , 那么 Z 就是一个 d×T 的矩阵,其中每一列 z→t 是一个 d 维的列向量。写成矩阵形式之后:
Z⊤=[z→1⊤⋮z→T⊤]=[q→1⊤⋮q→T⊤][k→1,⋯,k→T][v→1⊤⋮v→T⊤]=(Q⊤K)V⊤
其中, Q⊤∈RT×d , K∈Rd×T , V⊤∈RT×d 。
看上去很美好,注意力权重组成的是 T×T 的矩阵,它会将 V “完整地”映射到和它相同维度的空间中。但事实果真如此吗?根据矩阵乘法结合律, KV⊤ 是 d×d 的矩阵。用了乘法结合律之后,这个式子变成了
z→t⊤=q→t⊤(∑i=1Tk→iv→i⊤)=q→t⊤WKV,t=1,2,⋯,T
其中
WKV=∑i=1Tk→iv→i⊤∈Rd×d
是一个 d×d 的矩阵,而且是与 t 无关的。这意味着,我们完全可以首先把 WKV 计算出来 (复杂度是 O(T) ),然后再逐个应用到 q→t 上,复杂度仍是 O(T+T)=O(T) 。和标准的 Attention 不一样,这是一个线性复杂度的模型!事实上,这正是 Linear Attention。
既然是线性复杂度的模型,那从计算复杂度上考虑,它天然就会和 RNN 有类似的问题:无法完整捕捉每个字与整个句子的关系。事实上,如果考虑流式的输入,把 WKV 的求和上限从输入终点 T 改成 t 的话,那么
z→t⊤=q→t⊤(∑i=1tk→iv→i⊤)=q→t⊤WtKV
其中 WtKV 满足
WtKV=Wt−1KV+k→tv→t⊤
至此我们就揭开了 Linear Transformer 的真实面目:如果禁止 zt 参考后文 (从而求和只能到 t 而不能到 T ) 的话,那 WtKV 不是别的,正是 RNN 的中间状态。这件事情就变成了,每读取一个字 x→t ,中间状态 WtKV 就更新一次,然后输出 z→t 。
所以问题出在哪里?当我们考虑很长的输入 T≫d 时,可以发现,线性注意力的权重 Q⊤K 的秩不会大于 d ,而远小于 T 。这种低秩矩阵的状态会严重影响 z→t 的”丰富程度”,从而降低其所蕴含的信息量。
那么 Softmax 函数是怎么解决这个低秩矩阵的问题的?很简单,对于矩阵的每个元素都求指数并归一化,这是个典型的非线性操作。线性代数可没研究过这种非线性行为,这种操作完全有可能把一个稠密的低秩矩阵变成满秩的矩阵。
那只要非线性就可以了吗?我们最后来看看,到底是 Softmax 的哪一步能提升矩阵的秩。考虑函数 f 满足
f(Q⊤K)=ϕ(Q)⊤ψ(K)
也就是说,它可以拆分成两个矩阵各自对应函数的乘法。那么,此时在计算注意力权重时,考虑
z→t=∑i=1Tαtiv→i=∑i=1Tϕ(q→t)⋅ψ(k→i)∑j=1Tϕ(q→t)⋅ψ(k→j)v→i
也就是说,把 eq→t⋅k→i 这种内积整体的指数函数,拆分成了先进行非线性函数计算,然后再进行内积计算的形式。注意,原来的指数函数本身是不能这么拆的,这里是把指数函数替换成了一个能拆的非线性函数。除了分母上的 d 之外,它与原始的注意力机制就仅仅只有”可分离性”这点差别,而没有其他任何差别了。同样有非线性,也同样有分母的归一化。
我们来证明,这仍是 Linear Attention。
令 Φ(Q)=[ϕ(q→1),…,ϕ(q→T)]⊤ 和 Ψ(K)=[ψ(k→1),…,ψ(k→T)] ,则分子部分可表示为 ϕ(q→t)⊤ψ(k→i)=[Φ(Q)Ψ(K)]ti 。归一化因子可展开为:
∑j=1Tencϕ(q→t)⋅ψ(k→j)=ϕ(q→t)⋅S,S=∑j=1Tψ(k→j)∈Rd
这是一个全局统计量,与 t 无关。将注意力权重代入输出计算:
Z⊤=[ϕ(q→1)ϕ(q→1)⋅S∑i=1Tψ(k→i)v→i⊤,…,ϕ(q→T)ϕ(q→T)⋅S∑i=1Tψ(k→i)v→i⊤]
定义 W=∑i=1Tψ(k→i)v→i⊤ ,则输出简化为:
Z⊤=Φ~(Q)⋅W,Φ~(Q)=[ϕ(q→1)ϕ(q→1)⋅S,…,ϕ(q→T)ϕ(q→T)⋅S]
现在来看复杂度。
- 计算 S 的复杂度为 O(Td) ;
- 计算 W 的复杂度为 O(Td2) ;
- 计算 Φ~(Q) 的复杂度为 O(Td) ;
- 最终矩阵乘法的复杂度为 O(Td) ;
总时间复杂度为 O(Td2) ,属于线性复杂度。因此,即使引入非线性变换和归一化,该机制仍属于 Linear Attention 的范畴。至此,我们可以下结论了:正是 Softmax 中指数函数不可拆分的特性,让低秩矩阵变得具有更高的秩,从而保障了 Transformer 能正确给出字与字两两之间的关联。
当然,在 Softmax 中分母进行归一化则可以让数值更加稳定 (注意力权重处于 0 到 1 之间),而且能尽可能地把那些与当前字 z→t 不太关联的字 x→i 的权重趋于 0 (这是 Softmax 函数的特性,只有最大的几个值能显著大于 0),从而让 Transformer 能够更加聚焦于少数几个关键的概念。
可以注意到,这一点和多头注意力机制产生了奇妙的联动:多头注意力只有在像 Softmax 这种非线性函数中才有实际的作用,而另一方面,正是 Softmax 函数极度稀疏的特性,才使得我们需要引入多头注意力,让权重不要过于稀疏,从而能以多个角度关注不同的概念。
5.1.5 点积缩放的作用
在自注意力机制中,点积除以 d (在多头注意力中是除以 d/h ) 的主要作用是保持数值稳定性。假设 q→t 和 k→i 的每个分量都是独立同分布的随机变量,均值为 0,方差为 1。那么点积的期望为 0,方差为 d 。因此,对点积除以标准差 d ,即可提升不同维度向量作点积的数值稳定性。
下面我们来证明点积的方差为 d 。我们有
Var[q→t⋅k→i]=Var[∑j=1dqjtkji]
由于 qjt 和 kji 是独立同分布的随机变量,且不同维度之间相互独立,因此方差可以拆分为各维度方差之和:
Var[q→t⋅k→i]=∑j=1dVar[qjtkji]
根据方差的性质,对于独立随机变量 X 和 Y ,有
Var(XY)=E[X2]E[Y2]−E[X]2E[Y]2
因此:
Var[q→t⋅k→i]=∑j=1d(E[qjt2]E[kji2]−E[qjt]2E[kji]2)
根据题设, qjt 和 kji 均值为 0,方差为 1,即 E[qjt2]=E[kji2]=1 , E[qjt]=E[kji]=0 。代入得:
Var[q→t⋅k→i]=∑j=1d(1×1−0×0)=∑j=1d1=d
可以看到,点积的方差随着维度 d 线性增长。当 d 较大时,点积的绝对值会变得很大,这会导致 softmax 函数的输入值过大,使得梯度变得非常小(梯度消失问题)。通过除以 d ,我们可以将点积的方差归一化为 1:
Var[q→t⋅k→id]=1
这样处理后,Softmax 函数的输入值保持在合理的范围内,有利于梯度的传播和模型的训练。
再一次提醒,对于 Softmax 函数而言,用 d 把向量内积的值控制在一定范围内非常重要。因为所有的内积都同步扩大某个倍数的话,它的输出值会变得极为稀疏,只有最大的那个值会被保留下来,取值为 1 (嗯,从 Softmax 变成 Hardmax 了……)。毕竟这里所扩大的倍数实际上会作用在 e 的指数上面。
5.1.6 自注意力模块的反向传播
现在我们来正面回答题主所问的问题。当我们按照之前的写法,把输入写成向量序列(而不是Q、K、V三个长度可能会变化的矩阵)的时候,一切就明朗了。
在一切计算开始之前,需要先明确一个概念,即模型的参数量规模是固定死的。因而,即便自注意力层看上去能处理任意长的输入序列,但实际上这里的模型参数只负责处理单个词向量。对每个词向量而言,维度是固定的 d ,因此模型的参数量也是固定的 d×d (不考虑多头的情况,多头则是 dh×d )。
那么既然每次推理都会按照固定的程序,依照这些固定数目的参数,进行前向运算;那么我们当然可以依照一般的反向传播手续完成训练。计算图并不会因为序列可以为任意长度而出问题,毕竟在反向传播的时候我们只需要关心模型参数的数目别变化就行了。
自注意力模块并不会有“可变数目的模型参数”这种奇怪的东西,一切都和普通的卷积神经网络没什么不同。实际上,单纯的卷积层其实也是可以处理任意长度序列的,此时我们照样可以安心计算卷积核中的某个参数所对应的梯度。
如果实在不放心,那么我们就来试着计算一个矩阵 WQ 的某个元素 WijQ ,作为模型参数的一部分,它的梯度。这部分推导中用带括号的上角标来表示向量的分量。首先,数据的流向大致是:
x→t and WijQ→q→t→αti→z→t→Output→Loss
所以反向传播可以写为
∂L∂WijQ=∑t=1T∑r=1d∂L∂zt(r)∂zt(r)∂WijQ
这其中, ∂L∂zt(r) 是我们讨论的自注意力模块之后的部分,不是我们现在负责的范围,所以我们不管它。而另一项可以继续展开
∂zt(r)∂WijQ=∑l=1d∂zt(r)∂qt(l)∂qt(l)∂WijQ
其中
∂qt(l)∂WijQ=∂∂WijQ∑m=1dWlmQxt(m)δmj=xt(j),∀i,l
现在我们只剩下了 ∂zt(r)∂qt(l) 。这部分的计算也没什么奇怪的地方,就是很烦,我们一步步算下来:
∂zt(r)∂qt(l)=∂∂qt(l)∑n=1Tαtnvn(r)=∑n=1Tvn(r)∂αtn∂qt(l)
其中
αtn=exp(∑ν=1dqt(ν)kn(ν)/d)∑μ=1Texp(∑λ=1dqt(λ)kn(λ)/d)
令 βtn=∑ν=1dqt(ν)kn(ν)/d ,则
∂αtn∂qt(l)=∂βtn∂qt(l)∂∂βtnexp(βtn)∑μ=1Texp(βtμ)
其中
∂βtn∂qt(l)=1d∂∂qt(l)∑ν=1dqt(ν)kn(ν)=1d∑ν=1dkn(ν)δνl=kn(l)d
而另一方面,令 γtn=exp(βtn) ,有
∂∂βtnexp(βtn)∑μ=1Texp(βtμ)=dγtndβtn∂∂γtnγtn∑μ=1Tγtμ=γtn∑ρ=1Tγtρ−γtn2(∑μ=1Tγtμ)2
其实到这就反向传播完了,所有变量在前向传播的时候都已经算好值了。比如
γtn=exp(βtn)=exp(1d∑ν=1dqt(ν)kn(ν))
以及
qtν=∑m=1dWνmQxt(m),knν=∑m=1dWνmKxn(m),∀t,n=1,⋯,T
这里的 WνmQ 和 WνmK 就是此时的模型参数的值,而 xt(m) 和 xn(m) 则是输入序列的词向量的分量。至此,所有的部分都由已知的值表示了,就完成了反向传播。
其实后面的这些具体的反向传播计算并不重要,也不需要看懂。重要的是,知道反向传播在数学上是针对逐个输入词向量或者生成词向量进行的(而不能按照 Q K V 矩阵的方式看待),这就够了,它就是对一个输入向量进行线性变换的层而已,后面再多东西都是花里胡哨、无关紧要的。
这一通计算可太无聊了,基本上就是顺着计算图进行深度优先搜索来的。唯一的感想就是爱因斯坦求和记号确实是伟大的发明。
5.2 编码器
完整的 Transformer 架构还是比较复杂的,我们这里先罗列一些名词。
- 它由编码器 (Encoder) 和解码器 (Decoder) 两部分组成,每个部分都包含多个相同的层。
- 每个编码器层由两个主要子层构成: 多头自注意力机制 (Multi-Head Self-Attention) 和前馈神经网络 (Feed-Forward Neural Network, FFN),每个子层都采用了残差连接 (Residual Connection) 和层归一化 (Layer Normalization)。
- 解码器层在编码器层的基础上增加了一个额外的多头交叉注意力机制 (Multi-Head Cross-Attention),用于关注编码器的输出。
- 整个架构通过位置编码 (Positional Encoding) 来保留序列的位置信息,并采用缩放点积注意力 (Scaled Dot-Product Attention) 作为核心计算单元。
这种设计使得 Transformer 能够并行处理整个序列,同时有效捕捉长距离依赖关系。
5.2.1 输入模块
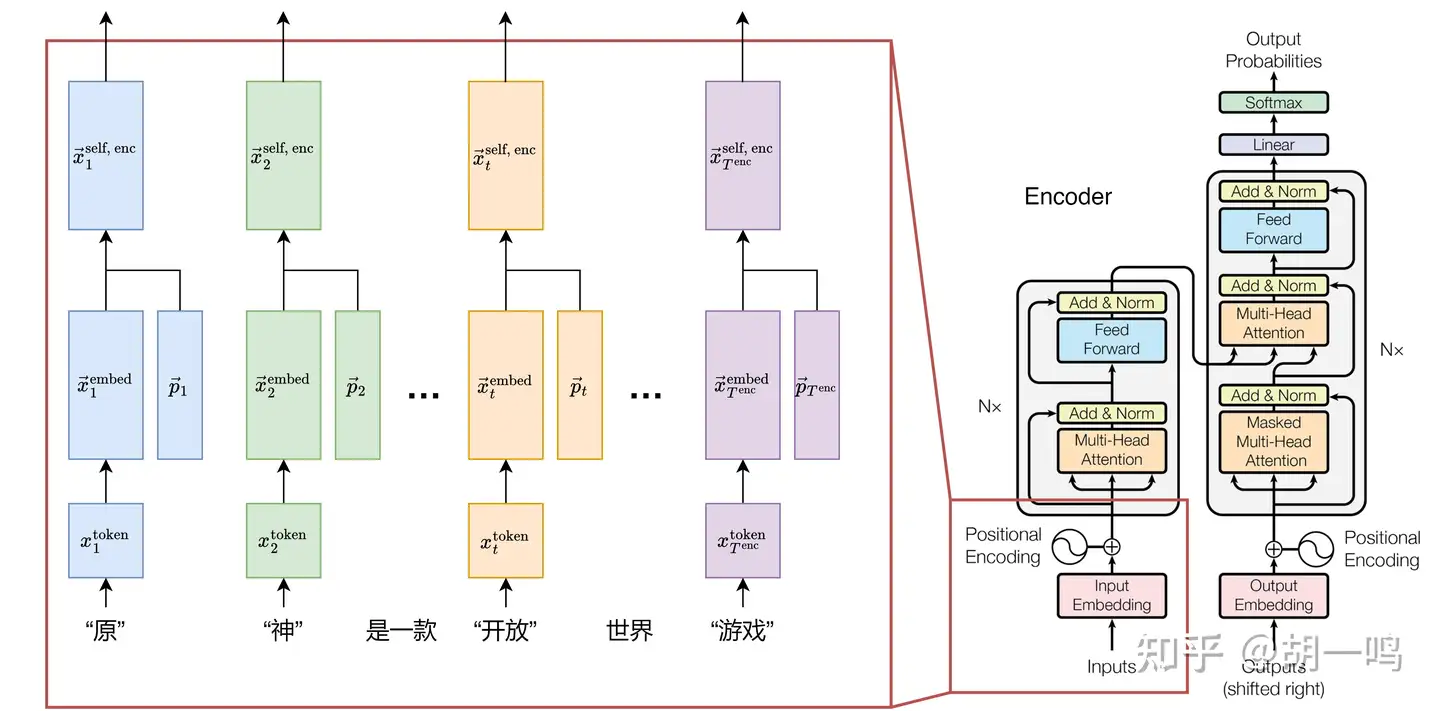
设输入的词元序列是 {xttoken}t=1Tenc , 其中每个 xttoken 是一个数字,表示固定词表中的某个词。然后,经过查表,可以映射为对应的词向量 {x→tembed}t=1Tenc ,其中 x→tembed 是一个维度为 d 的向量。接下来,加上位置编码向量 p→t 之后,即可得到第一个自注意力层的输入向量
x→tself, enc=x→tembed+p→t,t=1,2,⋯,Tenc
5.2.2 自注意力模块
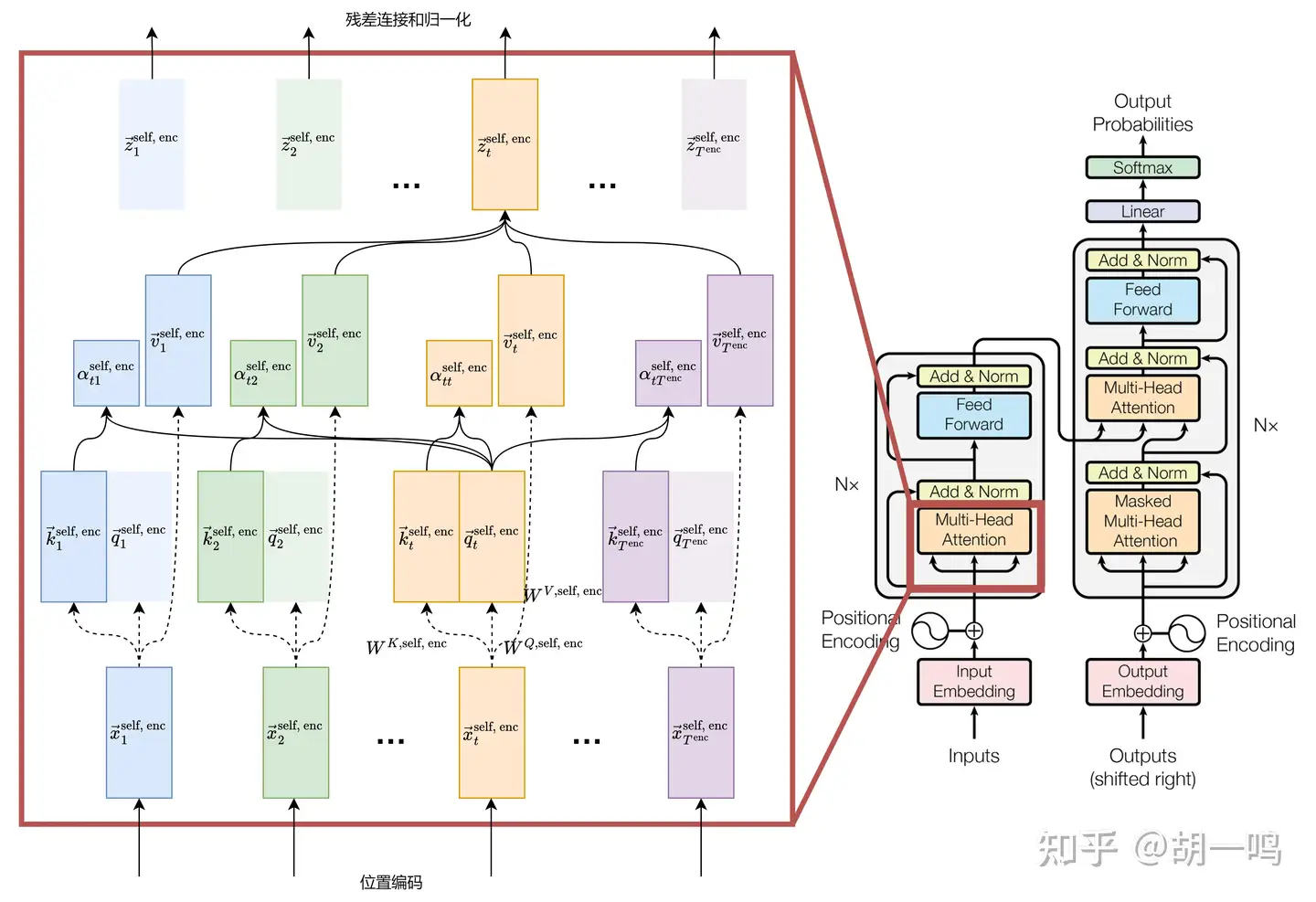
这里重新叙述一遍自注意力模块,加上角标以标明这里的量属于编码器的自注意力模块。
我们有
z→tself, enc=∑i=1Tencαtiself, encv→iself, enc,t=1,2,⋯,Tenc
其中 αtiself, enc 是注意力系数,满足
αtiself, enc=exp(q→tself, enc⋅k→iself, enc/d)∑j=1Tencexp(q→tself, enc⋅k→jself, enc/d)
而 q→tself, enc , k→iself, enc , v→iself, enc 分别是查询向量、键向量和值向量,满足
q→tself, enc=WQ,self, encx→tself, enc∈Rd,k→iself, enc=WK,self, encx→ienc∈Rd,v→iself, enc=WV,self, encx→ienc∈Rd
其中 WQ,self, enc∈Rd×d,WK,self, enc∈Rd×d,Wself, enc∈Rd×d 是编码器自注意力模块的参数。
注意,我们这里为了简化指标,没有把”多头”的部分给写出来。实际的实现中,不要忘了分成多头计算,每个头的矩阵的形状是 (d/h,d) ,所产生的查询向量、键向量和值向量的维度是 d/h 。然后把 h 个头进行拼接,再经过线性变换,才能得到多头注意力模块的输出 z→tself, enc 。
5.2.3 残差连接
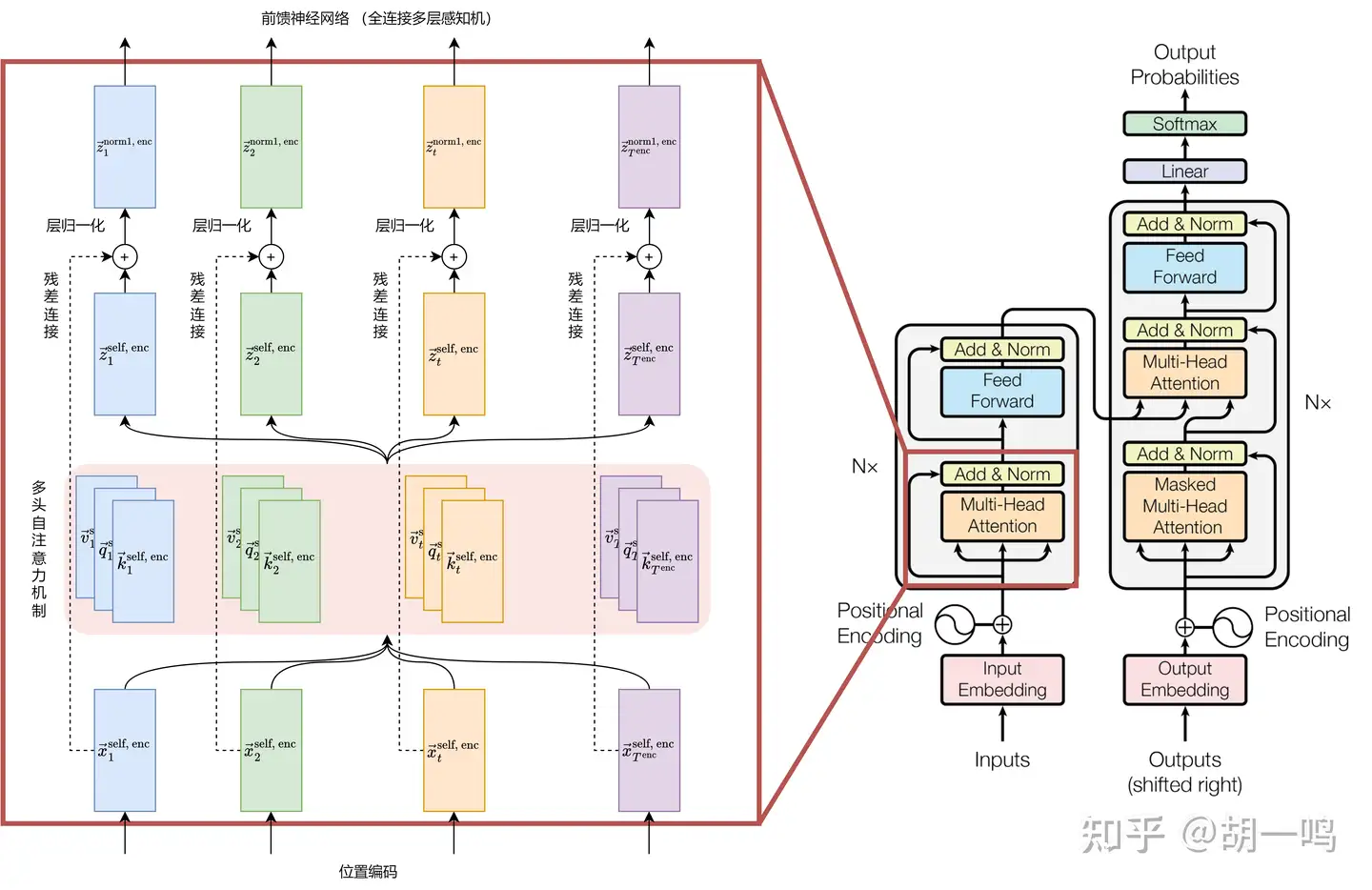
对于了解计算机视觉的人来说,残差连接是个再熟悉不过的概念,简单、优雅、深刻。它把任何花里胡哨的模型都变成了一阶微扰,从而保证它们在深度堆叠的过程中不会迷失自我。如果堆叠的某一层实在是不起作用,那么由于存在残差连接,它至少不会造成过于坏的影响,可以安心当它不存在,继续堆叠。在计算机视觉中,ResNet 通过残差连接,成功把卷积神经网络堆叠到上百层,并且训练效果相当不错。
所以遇事不决,引入残差连接就完事了,不要想那么多:
z→tres1, enc=x→tenc+z→tself, enc,t=1,2,⋯,Tenc
其中 x→tenc 是经过位置编码的、第一个多头注意力的输入词向量;而 z→tself, enc 是第一个多头注意力的输出。
5.2.4 层归一化
层归一化(Layer Normalization)主要用于解决深度神经网络训练过程中出现的内部协变量偏移问题。与批归一化(Batch Normalization)不同,层归一化是对向量的各个分量进行归一化,而不是在批次维度上。
具体来说,对于输入向量 z→tres1, enc∈Rd ,层归一化的计算过程如下:
z→tnorm1, enc=LayerNorm(z→tres1, enc)=γ→norm1, enc⊙1σt(z→tres1, enc−μt)+β→norm1, enc
其中 μt 和 σt 分别是输入向量各个分量的均值和标准差:
μt=1d∑j=1dzjtres1, enc,σt=1d∑j=1d(zjtres1, enc−μt)2+ϵ
而 γ→norm1, enc∈Rd 和 β→norm1, enc∈Rd 是可学习的缩放和平移参数,其实可以当作是一个简单的线性层啦。 ϵ 是一个很小的常数,放在分母上避免除 0 错误。
那么这里为啥不用批量归一化呢?主要是在这里批量归一化并不好做,每个”批量”、或者同一句话内,不同的词向量所表示的语义千差万别,做批量归一化意义不大。相对应地,对向量的各个分量进行归一化则有助于平衡各个分量之间的大小差异。
有人发现,层归一化如果不计算、减去均值 μt ,而只计算均方根 σt 并缩放,也几乎不影响效果,这种方法叫做均方根归一化 (RMSNorm):
z→tnorm1, enc=1σt(γ→norm1, enc⊙z→tres1, enc)
这里的 ⊙ 表示向量的逐元素乘法。总之大模型嘛,Scaling law 摆在那里,参数量和数据量上去了,有些操作加不加,效果几乎都没区别。那能减少一点计算量就减少一点咯。
另外,关于到底是像我们这里说的那样,先计算残差连接再进行层归一化 (叫 Post Norm)呢?还是先计算层归一化再算残差连接 (叫做 Pre Norm)?一般认为 Post Norm 的效果会更好一点,不过我也不知道为什么……
5.2.5 前馈神经网络与激活函数
为了增强模型的表达能力,通常在多头自注意力层之后会添加一个前馈神经网络 (Feed-Forward Neural Network, FFN),它由两个全连接层、中间夹着激活函数组成:
z→tffn, enc=Wffn2, encσ(Wffn1, encz→tnorm1, enc+b→ffn1, enc)+b→ffn2, enc
其中 Wffn1, enc∈Rdffn×d 和 Wffn2, enc∈Rd×dffn 是 FFN 的权重矩阵, b→ffn1, enc∈Rdffn 和 b→ffn2, enc∈Rd 是偏置项。 dffn 是前馈网络的隐藏层维度,通常 dff=4d ,意味着这里有一个升维然后降维的过程。
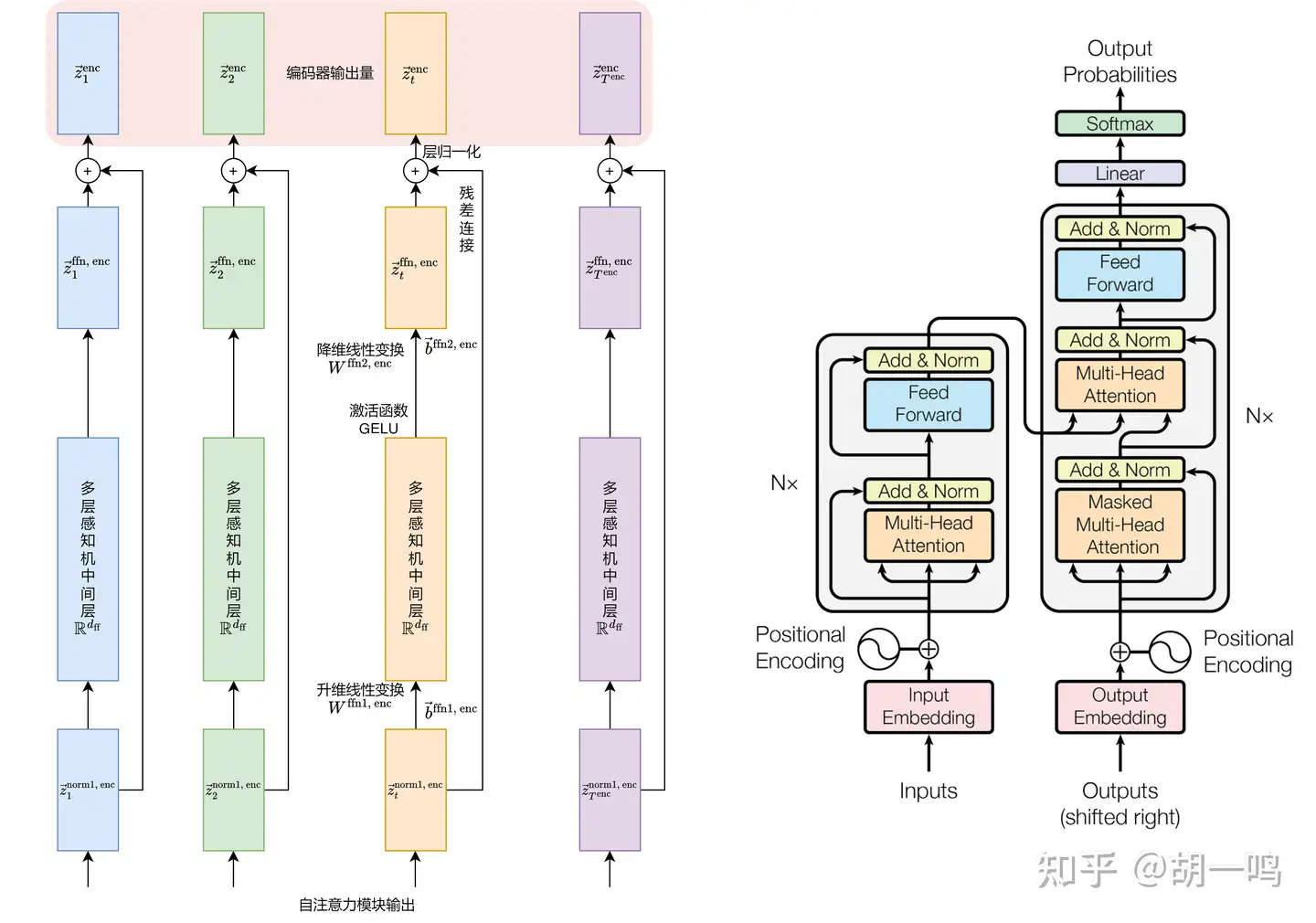
FFN 中的 σ 是激活函数,通常为 GELU (Gaussian Error Linear Unit),其定义为:
GELU(x)=xΦ(x)=x⋅12[1+erf(x2)]
其中 Φ(x) 是标准正态分布的累积分布函数, erf 是误差函数。
GELU 可以近似表示为:
GELU(x)≈0.5x(1+tanh[2π(x+0.044715×3)])
GELU 长得和 ReLU 类似,但比 ReLU 在零点附近更平滑,因此反向传播的数值稳定性要好一些。
在经过 FFN 之后,我们发挥传统艺能,遇事不决上残差和归一化:
z→tnorm2, enc=LayerNorm(z→tnorm1, enc+z→tffn, enc),t=1,2,⋯,Tenc
5.2.6 编码器输出
至此,便得到了Transformer第一层编码器的输出:
z→tenc=z→tnorm2, enc,t=1,2,⋯,Tenc
基本上,一层编码器就按照这个顺序计算:输入词向量,计算多头自注意力,残差归一化,再计算FFN,再残差归一化。这种编码器堆叠好几层,最终就可以得到编码器的输出。这是 Tenc 个 d 维向量,表示了输入序列中,每个位置处在句子中的语义结果。
可以看到,编码器全程没有涉及到任何递推的机制,所有的计算对于不同 t 而言都是平权的、不相互依赖的,只需要保证不同层之间的先后计算顺序即可,因而可以实现关于句子的并行计算。
反观 RNN,在读取时,除了不同的层之外,还需要保证不同 t 之间的计算顺序。这就意味着,RNN 每次读取一个词元的时候,都只能进行小规模的矩阵计算,却要从显存中读取模型全量的参数,因而负载全在显存带宽上了。
一般来说,典型训练所用的 GPU 的算力要比显存带宽高很多。比如对于 Nvidia A100 而言,其 BF16 算力是 312TFlops,而显存带宽则为 2 TB/s。极端情况按照一次 BF16 浮点运算需要读取两个数字 (4个字节) 来算, 差距是 624 倍。因此,最能压榨 GPU 性能的方式,是输入数据只从显存读一遍,但是每个数字都可以复用,都需要进行连续的、大量的计算。
n 维矩阵乘法就是能比较有效地利用算力的例子,需要读取的数据量是 O(n2) ,却需要进行 O(n3) 次计算。当 n 较大时,每秒需要进行乘法计算的次数,就超过了需要每秒读取数字的数据量,对于 GPU 而言这就是计算密集型的而非访存密集型的。
而逐元素乘法则是无法有效利用算力的反面例子,因为这仍要读取 O(n2) 的数据量,但却只进行 O(n2) 次乘法运算。换句话说,但对于 GPU 而言,当 n 较小时,我们会发现尽管矩阵乘法需要的运算量明显更大,其所花费的时间居然是和逐元素乘法是差不多的。只有当 n 很大了,矩阵乘法所多出的额外计算量才会成为 GPU 的负载,使得它所消耗的时间比逐元素乘法要长一些。
所以说,这是 Transformer 相对于 RNN 的一大改进,它基本上把读取句子时的计算,从访存密集型转换成了计算密集型,从而能在训练时充分利用 GPU 的算力。因此,尽管 Transformer 的计算量随着上下文长度的增长呈现平方增长,但 Transformer 仍比 RNN 更容易实现大规模的训练。同样规模的模型,只要在训练时每次读取的句子长度不太大,这些平方增长的计算量所消耗的时间,都要小于 RNN 因为逐字计算,而必须依靠缓慢的显存带宽所消耗的时间。
5.3 解码器
现在来研究解码器。解码器比编码器还要麻烦一点,因为它需要同时处理自己已经生成的词以及来自编码器的输入,同时还要负责输出。
5.3.1 解码器输入
在编码器中,我们设输入的词元是 {xttoken}t=1Tenc 。而在解码器中,我们则设 {yttoken}t=1Tdec ,其中 y1 是一个固定的词元 (BOS),表示解码器预测的开始。现在,解码器已经生成了一些词元了,刚刚生成了 yτtoken 。
我们这里有必要区分一下 τ 和 Tdec 。在解码器推理的时候, Tdec 是没有意义的,只有 τ 表示当前刚刚生成的那个最新的词元。而 Tdec 作为一个比 τ 大的数字,只在训练时才有意义,因为此时我们会给模型一整段文本去做训练,从而会需要考虑 τ 后面的那些词元。
我们先考虑推理,所以把 Tdec 给抛诸脑后。
现在,我们和编码器的输入类似,设解码器已经输出的词元为 yttoken ,其中 t=1,2,⋯,τ ,其对应的词向量是 x→tembed, dec ,在加了位置编码之后的词向量为 x→tself, dec ,作为解码器的掩码自注意力层的输入。解码器即将生成词元 yτ+1token ,这是需要通过预测第 τ+1 个词元的分数 y→τ+1ouput∈RN 经过 Softmax 归一化为概率分布之后,采样得到的。注意这里的 N 是词表长度。
5.3.2 自注意力模块推理
这实际上是一个递推的过程,我们只需要计算 z→τ 即可,因为 z→τ−1 以及更加之前的项是不会被用到的。
z→τself, dec=∑i=1τexp(q→τself, dec⋅k→iself, dec/d)∑j=1τexp(q→τself, dec⋅k→jself, dec/d)v→iself, dec
其中
q→τself, dec=WQ,self, decx→τself, deck→iself, dec=WK,self, decx→iself, dec,i=1,⋯,τv→iself, dec=WV,self, decx→iself, dec,i=1,⋯,τ
形式上和编码器的自注意力差不多,只不过这里只需要计算一个 z→τself, dec ,而编码器的自注意力那里需要计算从 1 到 Tenc 的所有 z→tself, enc 。
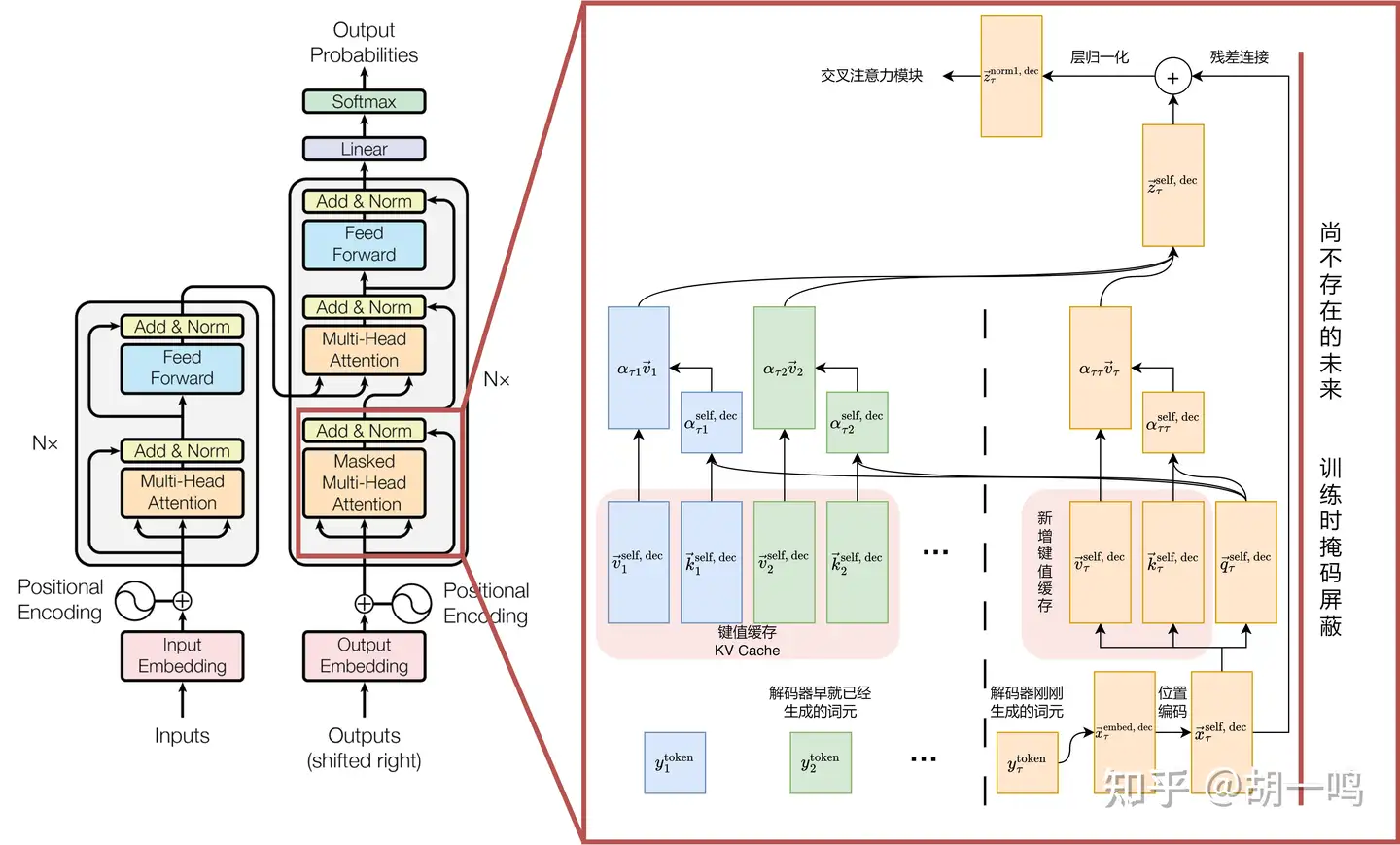
这里没有写上多头注意力的公式,因为我实在是不想写各个头的指标了。只需要记得,这里是需要区分多头的, e 指数上的分母实际应该是 d/h ,算完了之后还得拼接起来再线性变换一下即可。
仔细看一下上面的自注意力公式可以发现,对于 i=1,⋯,τ−1 而言, k→i 和 v→i 在之前的时间步中曾经被算过了。所以,如果把这些向量给缓存起来,那么我们就不需要重复计算 k→i=WKx→i 以及 v→i=WVx→i 这些式子了,只需要计算 k→τ 和 v→τ 即可。这个就叫做键值缓存 (KV Cache)。
5.3.3 键值缓存
所以有个经典问题,在解码器推理的时候,为什么需要缓存 K 和 V 矩阵 (KV Cache),不需要缓存查询矩阵 Q 呢?
那当然是因为,我们在每一步中,都只需要最新的那个 z→τself, dec 啦,而它只和最新的 q→τ 有关,与之前的 q→1,⋯,q→τ−1 都没有关系。
梳理一下,考虑 KV Cache,我们在计算 z→τself, dec 时,需要进行这些计算:
- 计算 q→τ、k→τ 和 v→τ ,关于时间步的复杂度 O(1)
- 读取之前已经算过了的 k→1,⋯,k→τ−1 以及 v→1,⋯,v→τ−1 ,关于时间步的复杂度 O(τ)
- 计算点乘注意力分数,即对于 i=1,⋯,τ ,计算 Softmax(q→τself, dec⋅k→iself, dec/d) ,关于时间步的复杂度 O(τ)
- 将注意力分数作为 v→i 的系数,计算z→τself, dec ,关于时间步的复杂度 O(τ) 。
最终,在推理第 τ+1 个词元时,需要计算 z→τself, dec ,其复杂度为 O(τ) 。因而,若要推理总长度为 Tdec 的句子,总的复杂度为 O(Tdec2) 。
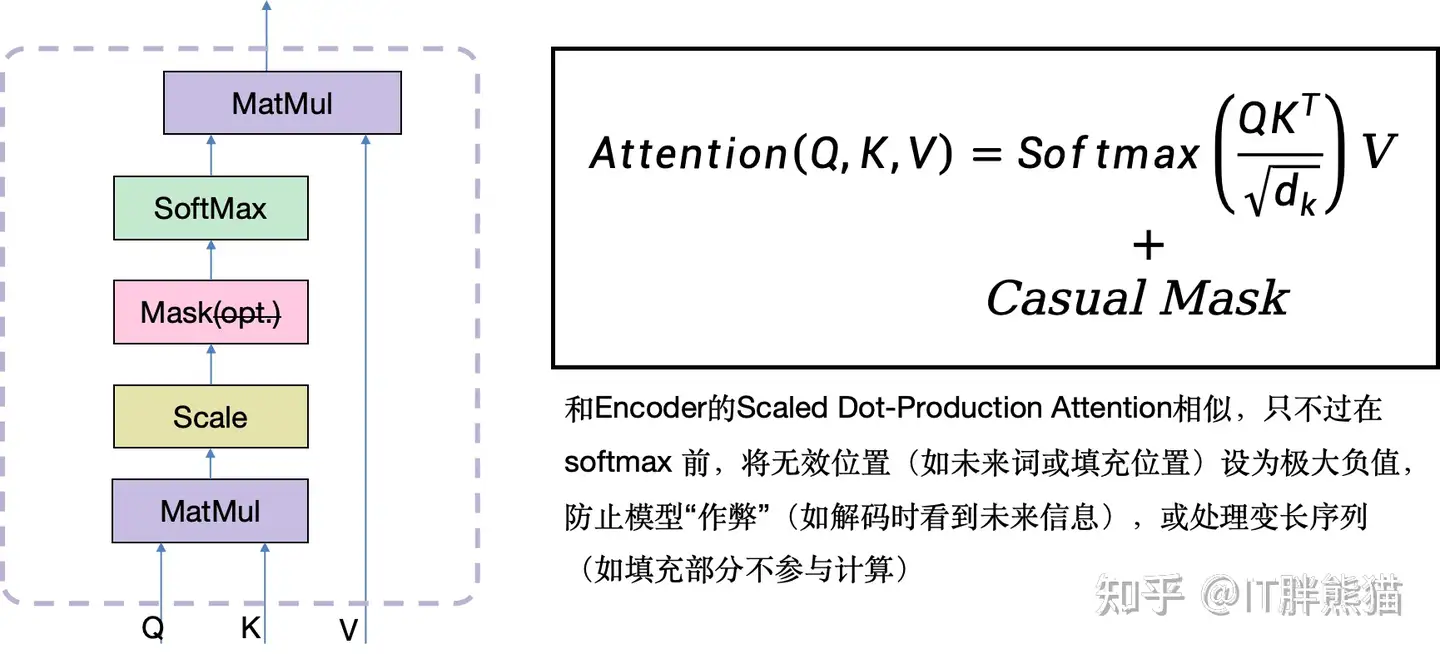
5.3.4 掩码自注意力机制
先前我们在解码器的自注意力机制中,介绍了在推理时的情形。那时,我们很自然地只需要考虑 1 到 τ 这些解码器已经生成了的词元,而不需要考虑之后的词元所对应的 y→τ+1self, dec 及其对应的 key 向量和 value 向量等等。毕竟,这些东西根本还不存在呢。
而在训练的时候,我们采用的是 teacher forcing 的办法。此时,我们会有一串回答的目标文本 yτtarget ,而解码器并不需要从头到尾预测整个句子 (因为那样中途错了一个词元,后面可能就全错了),只需要根据已经给出的目标文本,来预测下一个词元即可。这样就算中途预测错了,下一个词元也不会受到这个错误预测的影响。
既然在训练时,我们能拿到一整个句子的文本,意味着我们此时能直接计算一整个句子所对应的 k→itarget 和 v→itarget 向量,其中 i=1,⋯,τ,⋯,Tdec 。
然而这是不符合解码器真实面临的推理任务的:它只能知道 τ 以前的那些词元,并且仅用这些词元来计算 z→τself, dec 。如果我们放任解码器在训练时能看到之后的那些字的话,它在训练的时候就相当于作弊了。
因此,模型预测第 τ+1 个词元时,仍然需要维持求和的上限为 τ ,而不是 Tdec :
z→τself, dec=∑i=1τατiself, decv→iself, dec
其中 ατiself, dec 是 q→τself, dec 和 k→itarget 计算注意力系数,也就是 Softmax 函数的结果。
在实际的代码中,我们往往会让模型去一次性训练整个句子,因此需要同时计算所有词元位置所对应的下一个词元,并与目标进行对比以进行训练。这时用变化的求和上限 ( τ ) 就不太讨喜了,所以可以引入一个掩码矩阵,使得求和上限统一为 Tdec ,方便并行计算:
z→τself, dec=∑i=1TdecIτiMaskατiself, decv→iself, dec,where IτiMask={1,if i≤τ0,otherwise
但其实如果把整个式子写开来的话,会发现这种形式其实是不对的。问题出在 ατiself, dec 上,它是有分母的。这种形式的掩码矩阵只能确保把对应的分子设为零,但是分母却无法将对应的项屏蔽为零。
所以,更加合理的做法是:
k→iself, dec=IτiMask, Infk→itarget,v→iself, dec=IτiMask, Infv→itarget
其中:
IτiMask, Inf={1,if i≤τ−∞,otherwise
这样,就可以在计算注意力分数的时候,使得任何对 i>τ 的 e 指数项都为零,不论是分子还是分母。
再次提醒,我们这里为了避免指标过于复杂,忽略了多头注意力的操作。实际上是需要分多个头计算的,然后还要拼接起来并进行线性变换。接下来,就是我们在编码器的自注意力模块中已经熟知的操作,即残差连接+层归一化:
z→τnorm1, dec=LayerNorm(z→τself, dec+x→τself, dec)
至此便完成了掩码自注意力模块。
5.3.5 交叉注意力机制
解码器在掩码自注意力模块之后,就走到了交叉注意力模块了。解码器正是在这一层接受并融合编码器的输出。之前的编码器的输出为一串向量 {z→ienc}i=1Tenc ,而上一个解码器的掩码自注意力模块的输出为 z→τself, dec 。于是,很自然地,我们可以把它们拼接在一起,作为交叉注意力模块的输入。
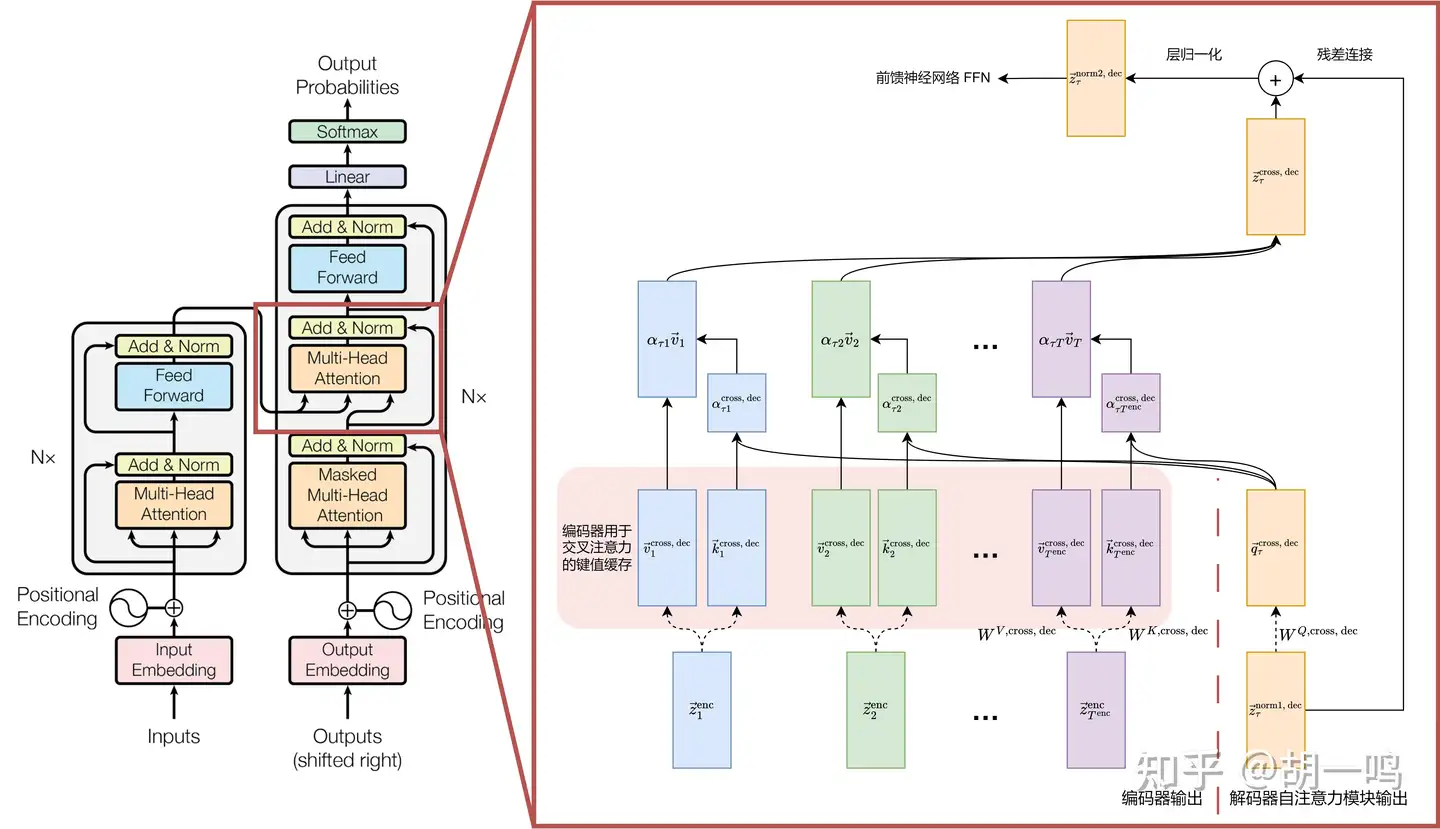
具体来说,查询向量 q→τcross, dec 来自解码器当前层的输出 z→τself, dec
q→τcross, dec=WQ,cross, decz→τself, dec
这是单个向量的线性变换。而键向量 k→icross, dec 和值向量 v→icross, dec 则来自编码器的输出 {z→ienc}i=1Tenc :
k→icross, dec=WK,cross, decz→ienc,v→icross, dec=WV,cross, decz→ienc,i=1,⋯,Tenc
这是 Tenc 个向量的线性变换。因此,交叉注意力机制的输出为
z→τcross, dec=∑i=1Tencατicross, decv→icross, dec,ατicross, dec=exp(q→τcross, dec⋅k→icross, dec)∑j=1Tencexp(q→τcross, dec⋅k→jcross, dec)
第三次提醒,为了避免指标过于复杂,我们这里忽略了多头注意力的操作。实际上需要分多个头计算的,然后还要拼接起来并进行线性变换。接下来,仍是残差连接和归一化:
z→τnorm2, dec=LayerNorm(z→τcross, dec+z→τnorm1, dec)
5.3.6 解码器输出
和编码器一样,解码器在输出之前,还得经过一轮FFN激活函数、残差连接和归一化。
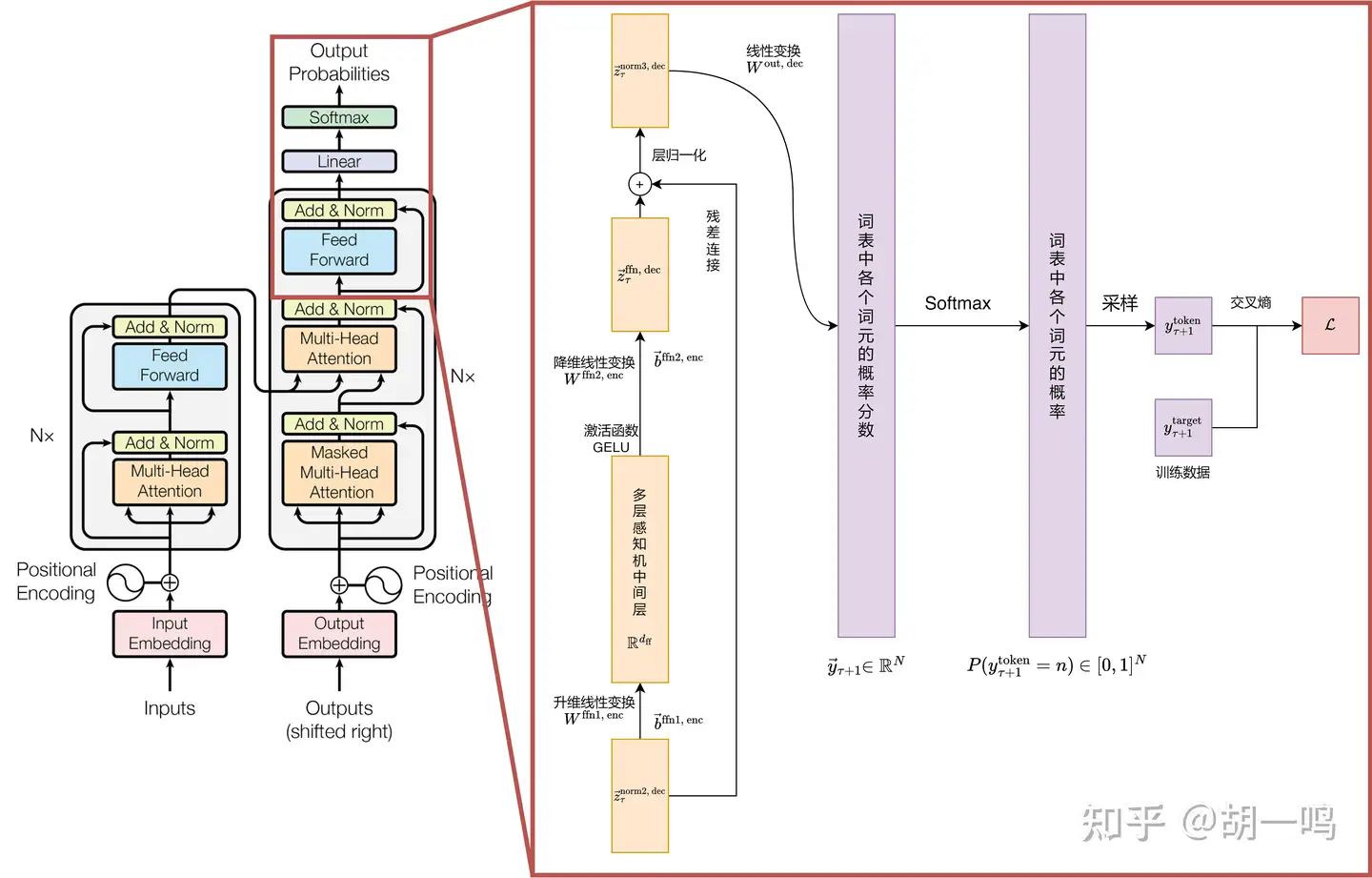
首先是 FFN:
z→τffn, dec=Wffn2, decσ(Wffn1, decz→τnorm2, dec+b→ffn1, dec)+b→ffn2, dec
其中 σ 为 GELU 激活函数。然后,是残差连接和归一化:
z→τnorm3, dec=LayerNorm(z→τnorm2, dec+z→τffn, dec)
这样,一层解码器层的输出就准备好了。实际上,由掩码自注意力模块、交叉注意力模块以及 FFN 激活函数构成的层会堆叠多次。最后,我们经过一个线性变换:
y→τ+1=Wout, decz→τnorm3, dec
其中, y→τ+1∈RN 是各个可能的词元所对应的概率分数, Wout, dec∈RN×d 是一个线性变换的矩阵。正如我们在 RNN 或者 Seq2Seq 中熟知的,对概率分数求 Softmax 归一化后即可得到下一个词元的概率:
P(yτ+1token=n|{xttoken}t=1Tenc,{yitoken}i=1τ)=exp(yτ+1(n))∑j=1Nexp(yτ+1(j)),n=1,⋯,N
然后根据这个概率进行采样即可。其中, yτ+1(n) 是向量 y→τ+1 的第 n 个分量,也就是第 τ+1 个词元 (即将要预测的这个词元) 是词表中第 n 号词元的概率分数。概率中的条件 {xttoken}t=1Tenc 表示编码器的输入句子 (词元序列) ; {yitoken}i=1τ 表示解码器已经输出了的部分句子。
在训练时,和一般的类别预测任务一样,使用交叉熵来训练模型,即正确词元序号所对应概率的对数:
L=∑τ=1Tdec−1−logP(yτ+1token=yτ+1target|{xttoken}t=1Tenc,{yitarget}i=1τ)
注意我们这里的条件是用的 yitarget 而不是 yitoken ,也就是说拿训练样本中已经输出的内容作为条件。这里仍然体现的 teacher forcing 的思想,防止出现模型中途写错了一个字,后面就全错了,导致难以训练的问题。在实现的时候,前面的 τ 从 1 到 Tdec−1 求和,表示我们一般需要一次计算一整个目标句子。
https://www.zhihu.com/question/596771388/answer/125961795057
https://www.zhihu.com/question/596771388/answer/125961795057
IT胖熊猫 信息技术行业 产品规划专家
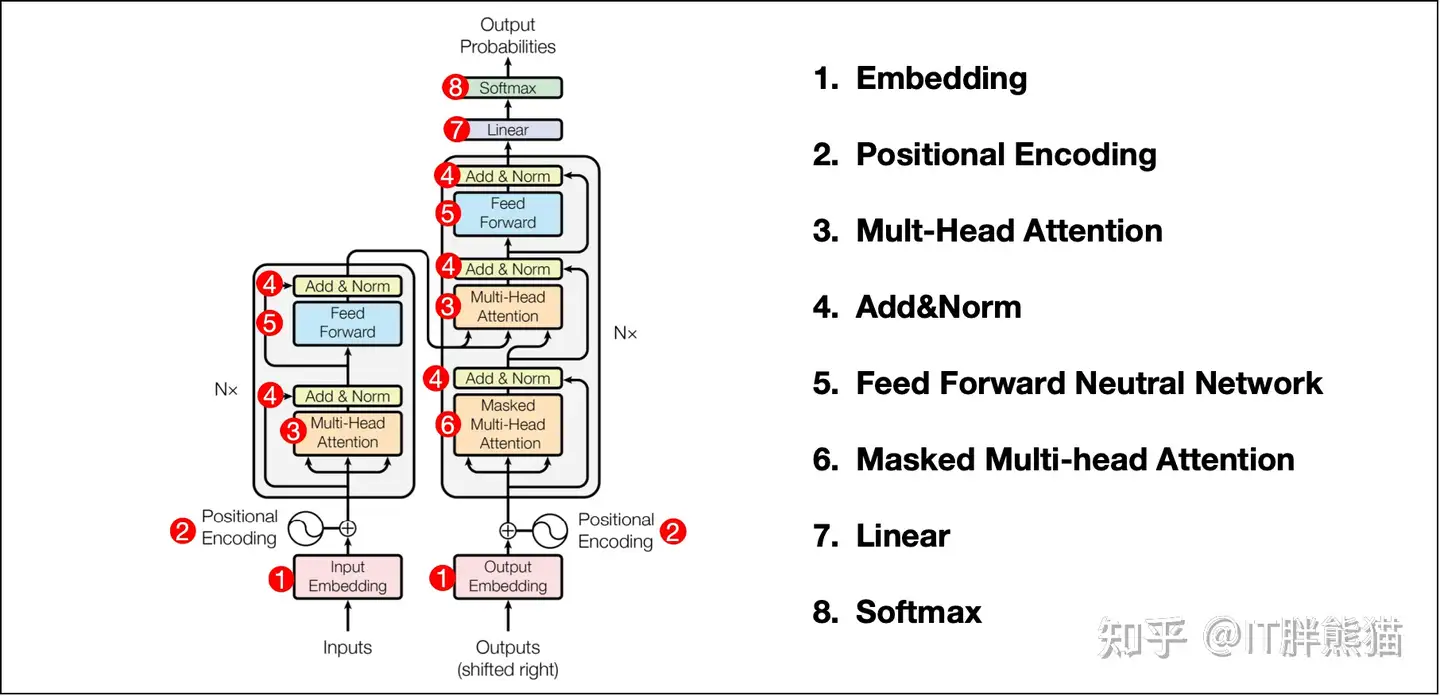
Transformer架构图
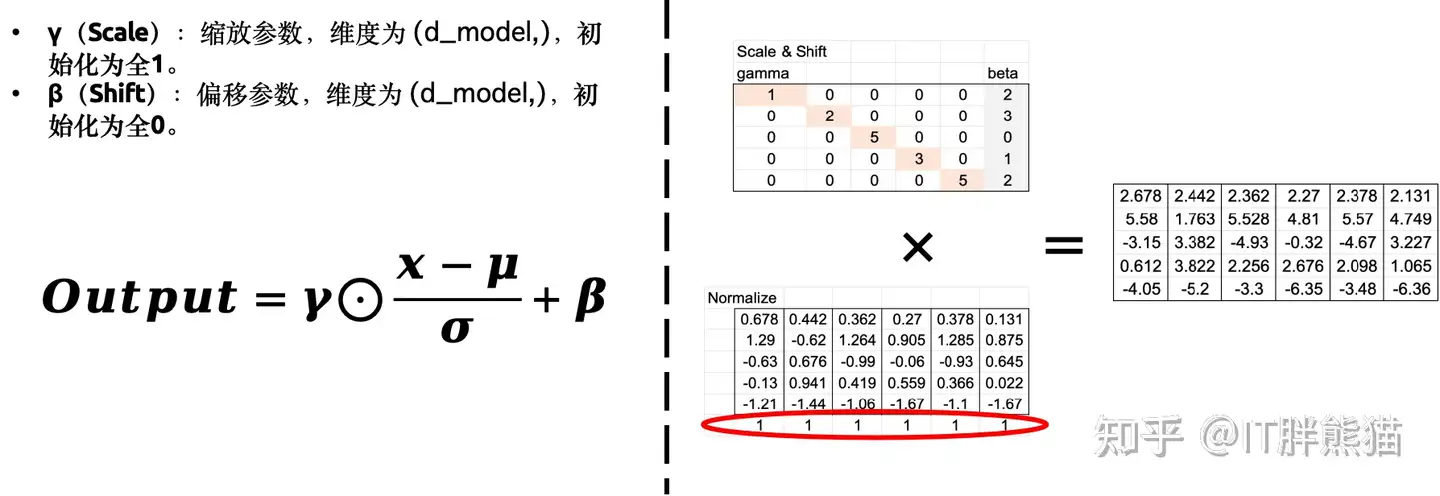
这里其实还有个操作在Add & Norm层中,叫做Scaled & shift(缩放和偏移),其核心作用是对输入数据进行标准化处理,以提高模型的稳定性和训练效率。
就是缩放+偏移值,效果就是提升模型的稳定度,这个是深度学习的技巧了,可以忽略。
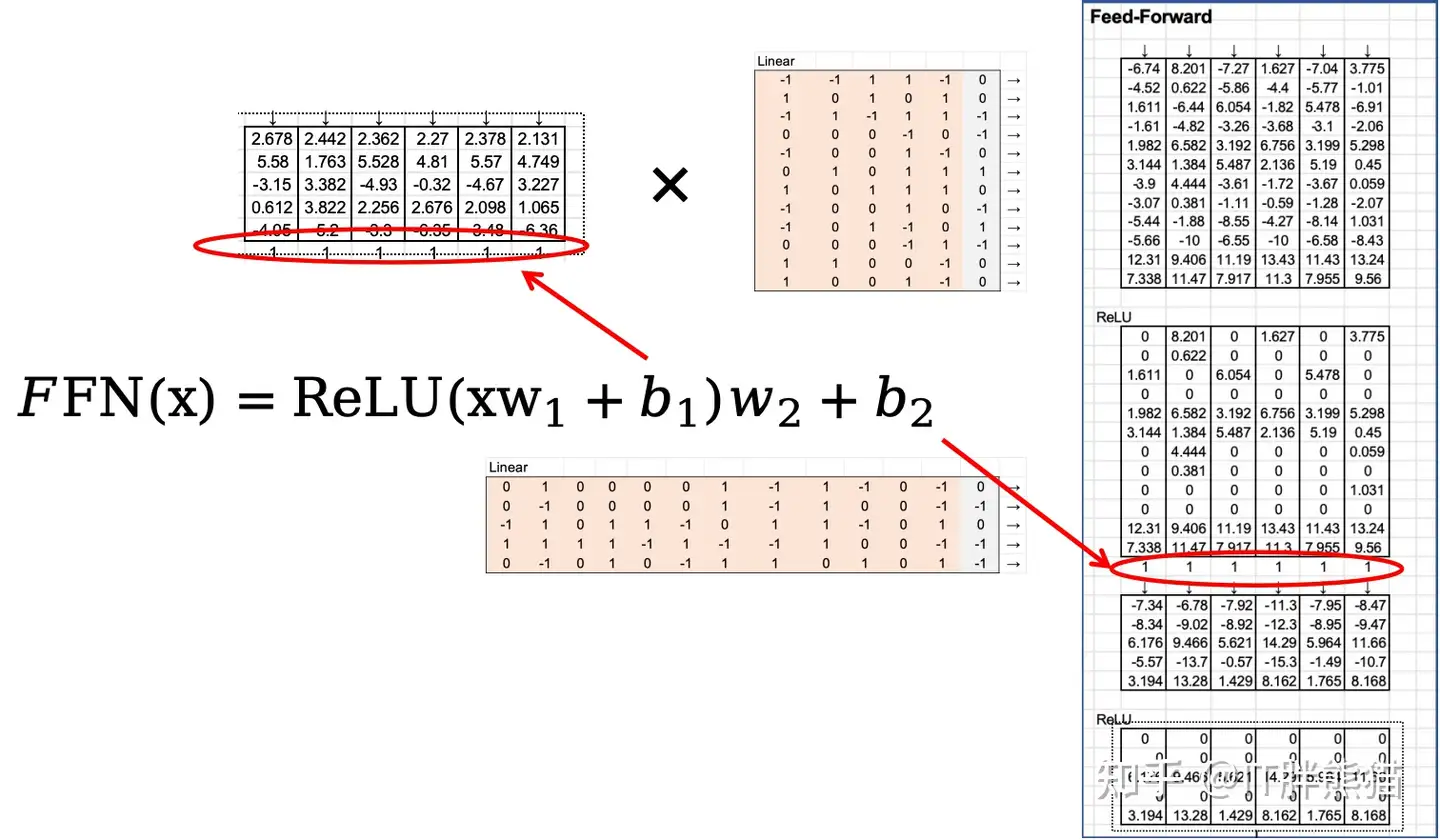
3.4 Feed Forward Neutral Network
以上注意力就完成了,我们走到下面的FFN(涉及到深度学习的部分我们先不展开,只要知道它是全互联就好了。)
- 第一层全连接:将输入升维到 4×dmodel4\times d_{model} ,这里放大 22 倍。
- ReLU:引入非线性,过滤负值。
- T5G08uEm”>第二层全连接:降维回 dmodeld_{model} 。
Decoder框架
Decoder部分和Encoder非常相似,可以看到除了前面的Masked MHA以外,和Encoder一摸一样的,
所以 Decoder = Masked MHA + Encoder。
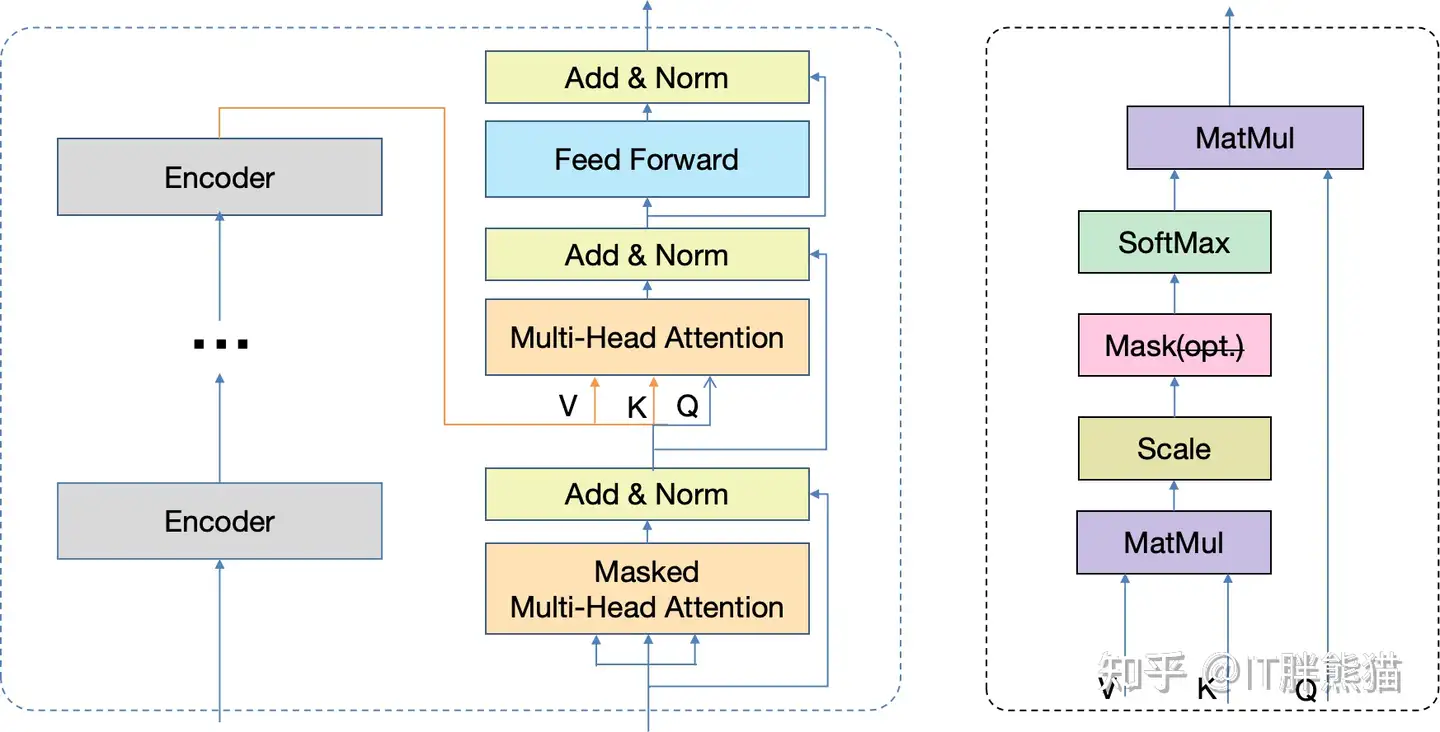
4.2 Masked Multi-Head Attention
其实Masked MHA的核心还是scaled dot-production attention,首先还是制备Q、K和V。
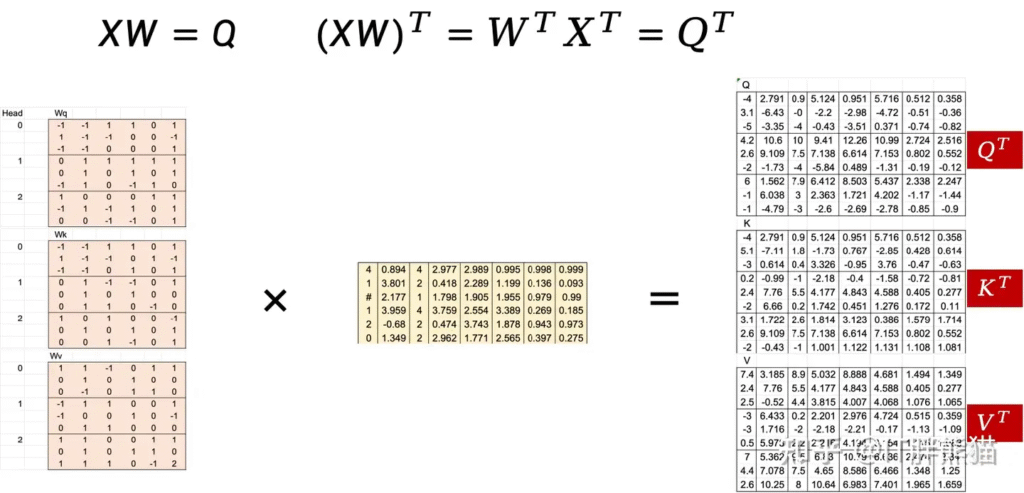

Transformer演化路径 | 来源:A Survey on ChatGPT and Beyond
作者:IT胖熊猫
链接:https://www.zhihu.com/question/596771388/answer/119375053579