这真是一个中国的奇迹,或者说中国就一直擅长创造这样的奇迹!
以前一直在工业领域:
- 高铁,2004年开始引进日本、德国,然后现在中国的高铁运营里程全球最长,技术领先,开始海外输出。
- 通信设备,1987年华为成立,从开始代理到自研,直到现在5G领域全球领先。
- 光伏,2000年初,基本是进口。现在到全球光伏产业全面领先。
- 电动车,2003年特斯拉开始,到现在全球最大的电动国汽车制造商已经换成了BYD,而我觉得国内最好的电动车汽车是“小米”!!

只是我没想到,我们创造的奇迹这么快在AI领域上演了!而且是在这样一个极端困难的情况下:
美国从芯片的小院高墙开始,到高端AI芯片的全面禁运!相当于,全面断供了中国的AI“军火”装备,把一切可能都变成了不可能的时候。
DeepSeek这个做金融的搞钱公司,把不可能,变成了Dream It Possible 真的变成了 Make It Possible.
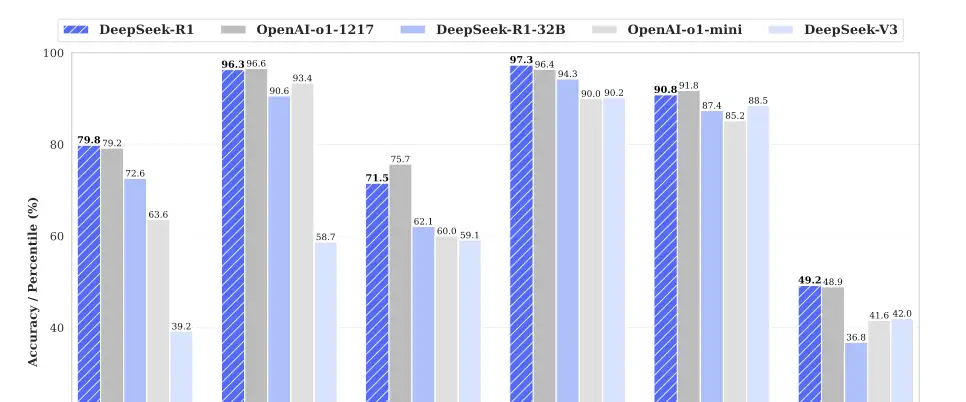
DeepSeek V3好多指标追平了 GPT-4o与Claude 3.5, 这两个基本上是全球的最主流AI大模型。
而DeepSeek R1 更是在数学、编程、科学推理等任务上达到或超越 OpenAI-o1-1217。这个可能仅是中国人的骄傲,而DeepSeek V3与R1的全面开源,才是真的变成了全人类的骄傲!
无论多么骄傲,还是要学会AI,并且投身AI才有饭吃吧。毕竟只有懂了,会了才有用。
为什么DeepSeek一出来,大家这么开心?因为明白人都清楚,未来只有AI,不会AI的人会马上被淘汰。只有学会了使用AI,与AI共存才能有未来,才能在未来有发展!
这里的发展包括收益、平台、职业高度等等,如果你想分得Al一杯羹,但只是了解,没有形成系统化的认知,也没有办法吃到AI的红利,我真的建议你认真的,系统学一下AI的核心知识:知学堂的AI大模型技术公开课,就特别适合这类需求的人,比如开发、算法、测试、架构、运维等,这一课程让你快速接触大模型,理解DeepSeek原理、底层算法,上手开发和微调DeepSeek大模型,带你快速掌握大模型的技术架构,还可以进行商业实战,点击下面卡片就能领取↓↓
现在DeepSeek 大热,说实话如果搞技术的都不了解其中的技术门道,确实就有点过分了,很多人学完掌握了实用的大模型技术,高薪去大厂完全没有问题,我自己认真听完后,在工作提效上也有很大的收获。
还是回到DeepSeek这个R1, 我们肯定是不能靠骄傲DeepSeek的R1在人工智能圈子混饭吃啊。还是要认真的学习一下DeepSeek的喂饭教程!
DeepSeek-R1-Zero/R1/蒸馏这三种核心技术的完全公开内容如下:
DeepSeek-R1-Zero(纯 RL 训练)
- 强化学习算法:采用 Group Relative Policy Optimization (GRPO),通过分组采样优化策略:
目标函数:
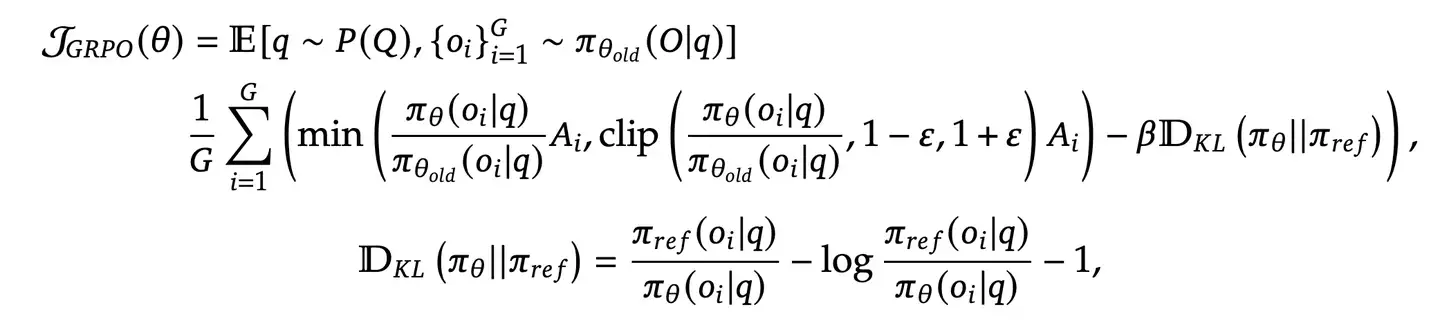
其中Ai来源于下面的计算算法。
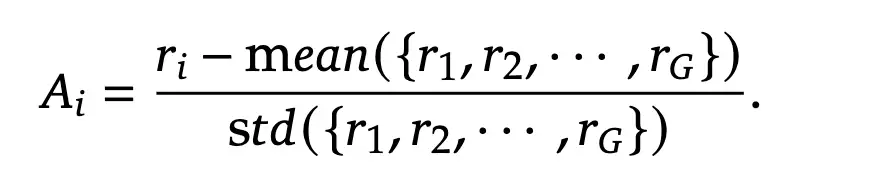
- 奖励模型设计:
- 准确性奖励:通过规则验证答案正确性(如数学问题的最终答案格式、代码编译测试)。
- 格式奖励:强制模型将推理过程包裹在 `<think>` 和 `<answer>` 标签中。
- 训练模板:使用固定模板引导模型首先生成推理链,再输出答案(模板见第6页)。

DeepSeek-R1(多阶段增强训练)
- 冷启动(Cold Start):
收集数千条高质量长链式思维(CoT)数据,通过 SFT 微调基础模型,提升初始可读性。
数据来源:人工标注、DeepSeek-R1-Zero 生成结果后处理、少样本提示生成。
- 推理导向的 RL:
在冷启动模型上应用与 R1-Zero 相同的 GRPO 算法。
新增 语言一致性奖励,减少多语言混合问题(通过目标语言占比计算)。
- 拒绝采样与 SFT:
RL 收敛后,通过拒绝采样生成 60 万条高质量推理数据,结合 20 万条非推理数据(写作、事实 QA 等)。
对基础模型进行两轮 SFT,增强多领域能力。
- 全场景 RL 对齐:
结合推理任务(规则奖励)和通用任务(基于奖励模型的人类偏好对齐),二次优化模型。
蒸馏技术
- 目标:将 DeepSeek-R1 的推理能力迁移至更小的密集模型(如 Qwen、Llama 系列)。
- 方法:
使用 DeepSeek-R1 生成的 80 万条数据(含推理与非推理样本)进行监督微调(SFT)。
支持 1.5B 至 70B 参数量模型(如 Qwen2.5-32B、Llama3.3-70B)。
- 效果:蒸馏后的 14B 模型超越 QwQ-32B-Preview,32B/70B 模型性能接近 OpenAI-o1-mini。
不仅仅喂了饭,DeepSeek还把自己的趟过的坑明明白白告诉大家了。
关键技术挑战与解决方案
- 可读性问题:通过冷启动数据中的结构化格式(如 `<reasoning_process>` 和 `<summary>`)和语言一致性奖励解决。
奖励滥用(Reward Hacking):采用规则奖励(非神经奖励模型)避免复杂调优。
训练效率:GRPO 算法省去价值模型(Critic),通过分组采样降低计算成本。
- 失败尝试:
过程奖励模型(PRM):因人工标注成本高、奖励滥用问题被放弃。
蒙特卡洛树搜索(MCTS):因搜索空间过大、价值模型训练困难未成功。
如果这你都觉得自己做不来R1相关的工作,那考虑一下转行做应用开发吧。
最后留几个国外的评价吧,这东西不是只有中国人认为好的!

可以说,仅凭DeepSeek就可以说美国单方面发动的AI战争,非但没能实现削弱中国的AI能力,反而还助力中国更好的发展出了自己的AI能力,甚至是中国人第一次站到了OpenAI的位置,我们做到了真正的OPENAI。世界需要的是DeepSeek,而不是一个越来越接近美国政府,美国军方,甚至连简单的信息都不开放的CLOSEAI(OpenAI)