导语
想象一下,在高维特征空间中,成千上万个词向量如同毫无秩序悬浮着的箭头。由于自注意力机制天生缺乏对序列顺序的感知,我们该如何为其注入时间之矢?许多开发者将旋转位置编码(RoPE)视作一个解决该问题的常规“工程 Trick”或黑盒 API,却未曾察觉其背后隐藏着极其优雅的几何与物理直觉——抛弃生硬的位置标签,让高维向量以特定的频率阵列进行正交旋转,仅凭向量间的“夹角”便能自然涌现出精确的相对位置感知。
RoPE 绝非单纯的代码拼凑,而是利用复数域和旋转群在多维空间中建立的一套严密数学系统。它不仅是 LLaMA、Qwen 等主流大模型卓越性能的基石,其独特的频率域特性更是当前所有长上下文外推技术赖以生存的土壤。若看不透这层数学本质,大模型长文本的优化与魔改便只能在盲目的调参中迷失。
本文将剥离浮于表面的泛泛科普,带你进行一次硬核的底层解构。我们将从复平面上的欧拉公式起步,升维跨入分块对角矩阵与正交群 的直和空间,用严密的推导证明内积振荡衰减所赋予的物理“距离感”。最终,我们会站在频率域的关键视角,彻底拨开 NTK-aware 缩放与 YaRN 等前沿外推技术的迷雾。如果你不满足于“知其然”,渴望看懂大模型代码背后的第一性原理,请做好准备,我们即刻启航。
1. 相对位置的数学圣杯:复平面上的欧拉公式
原生 Transformer 结构中的注意力机制本质上是一种基于集合(Set)的聚合操作,它天生就是一个“色盲”——对输入序列元素的顺序毫无感知。如果打乱输入句子的语序,模型计算出的注意力分数矩阵只是相应地做了行列置换,输出特征的集合本身并没有改变。为了打破这种置换等价性(Permutation Equivariant),让模型理解“词汇出现在序列的哪个位置”,引入位置编码(Positional Encoding)成为了大语言模型架构设计中不可或缺的一环。
自注意力的数学圣杯:寻找 g(q,k,m-n)
我们知道,在自注意力机制中,Query 向量(简称 q)和 Key 向量(简称 k )发生交互的核心操作是计算内积(Dot Product)。内积的大小决定了词与词之间关联度的强弱。在旋转位置编码(RoPE)提出之前,绝对位置编码(如 Sinusoidal 编码)和相对位置编码(如 T5 的 Relative Bias)各自为战。绝对位置编码实现简单,但缺乏对相对距离的直接建模;相对位置编码直接将相对距离注入注意力矩阵,却往往会破坏自注意力的高效并行计算机制。
RoPE 试图达成一个绝妙的“既要又要”:在输入端给 和 分别注入绝对位置信息,但在它们进行内积运算时,数学形式能够自然坍缩为仅与它们的相对位置有关。
用严谨的数学语言表述,假设我们有一个函数 f,它接收词嵌入向量和绝对位置标量作为输入。我们的终极目标是找到一种 f,使得引入绝对位置 的 与引入绝对位置 m 的 q 进行内积后,结果等价于某个只以原始向量 、 以及它们之间的相对距离 (m-n) 为自变量的函数 g:

这不仅是解开相对位置编码的“数学圣杯”,更是决定长上下文大模型能否稳定运行的根基。要在实数域中直接构造上述函数 并不直观,破局的第一步,是把目光从死板的实数向量,转向灵动的复平面。
降维思考:引入复平面的几何直觉
为了寻找突破口,我们不妨先做一个降维假设:假设词嵌入空间的维度只有二维()。任何一个二维实向量 都可以自然地映射到复平面上,表示为一个复数: 。

一旦进入了复数域,我们就获得了一件处理周期与角度的神兵利器——欧拉公式(Euler’s Formula):

在复平面的几何直觉中,乘以 等价于将复数向量绕原点逆时针旋转 角度,而绝不改变向量的模长(L2-Norm)。此时,如果我们把“位置”这个离散概念与“旋转角度”这个连续几何量绑定在一起,一切就豁然开朗了:我们可以规定,位于序列第 个位置的 token,其对应的向量在复平面上固定旋转 m() 的角度(其中 是某个预设的基础频率常数)。

于是,绝对位置信息的注入不再是生硬的向量加法运算(如经典 Transformer 所做的那样),而是变成了一种优雅的几何变换:旋转。Absolute in, Relative out(绝对位置输入,相对位置输出)的齿轮开始转动。
数学证明:内积的奇妙坍缩
有了复平面的几何直觉,我们需要用严密的代数推导来证明这种设计是否真的满足我们的终极目标 。
首先,回忆一下复数运算与实平面二维向量内积的等价关系。对于复数 和 ,它们的乘积(其中 为共轭复数)展开为:首先,回忆一下复数运算与实平面二维向量内积的等价关系。对于复数 和 ,它们的乘积(其中 为共轭复数)展开为:

提取其实部(),正好就是原二维实向量的标准内积:
现在,我们将前文构思的“旋转位置编码”代入。假设 Query 向量在绝对位置 ,经过旋转编码后的复数表示为 。同理,Key 向量在绝对位置 ,经过旋转编码后的复数表示为 。
当这两个带有绝对位置的向量在注意力机制中发生碰撞(计算内积)时,我们利用复数内积的性质:

将指数形式代入上式展开:
根据复数共轭的性质 以及欧拉公式的共轭 ,公式可以进一步化简为:
提取底数相同的指数项:
让我们停顿一下,仔细审视最后这一步的结果。括号里的部分由两块组成:一块是原始无位置信息向量的复数积 ,另一块是表示相对角度旋转的 。
奇迹出现了:原本相互独立的绝对位置标量 和 ,在复数共轭乘法的物理意义(相位差运算)作用下,完美地做差合并成了 。 如果我们用实数空间的三角函数将上式完全展开,最终的结果就是:
可以清楚地看到,最终的内积结果仅仅依赖于原始向量 q、k、 以及它们之间的相对位置 (m-N),完全不受它们所在的绝对位置 或 的偏移影响。这就是旋转位置编码(RoPE)名字的由来,也是它最核心的数学灵魂。
通过巧妙借用欧拉公式在复平面上的旋转性质,RoPE 在二维空间内完美解开了位置编码的“数学圣杯”方程。然而,现实中的大语言模型(如 LLaMA)往往拥有成百上千甚至上万维的隐藏层特征(Hidden States),二维空间的漂亮结论能否直接、稳定地推广到高维的工程师战场?要回答这个问题,我们需要引入李群与正交矩阵等更强大的数学工具。
2. 升维打击:分块对角矩阵与正交群 SO(2) 的直和
上一章中,我们在二维复平面上找到了位置编码的“数学圣杯”——利用欧拉公式将绝对位置转化为旋转角度,使得向量内积自然坍缩为相对位置的函数。但这仅仅是故事的起点。
在真实的工程实践中(例如 LLaMA、Mistral 等现代大语言模型),Token 的 Embedding 并不是二维的,而是高达 4096 甚至 8192 维的实数向量。我们如何将复平面上的优雅旋转,安全、无损且高效地“升维”到庞大的多维特征空间中?这正是本章要解答的核心问题。
降解高维复杂性:正交子空间的划分
在多维空间中定义一个单一的全局旋转变换是非常危险的。多维联合旋转会使得所有特征维度相互纠缠(Entanglement),不仅计算代价高昂,还会破坏大模型特征表示中原本的语义独立性。数学上的最高级智慧往往在于“解耦”。
RoPE 的作者采取了正交子空间划分的降维打击策略:将 d 维的高维空间,从逻辑上等价拆解为 d/2 个相互独立、互不干扰的二维平面的集合。

具体而言,对于一个 维的输入向量 ,我们可以将其按顺序两两分组,转化为 个二维向量对:

接着,我们在每个独立的二维子空间内,分别应用上一章推导出的二维旋转变换。这就好比在一座有 层的同轴复式钟楼里,每一层都有一个独立的表盘在按照自己的节律转动,信息被完美隔离。

矩阵的真正形态:分块对角矩阵的构建
如果我们用线性代数的语言来刻画这个严谨的升维过程,针对序列中绝对位置为 的 Token,其多维旋转操作可以表示为用一个矩阵 乘以输入向量 。
基于上述的子空间划分策略, 在 维空间中会呈现出极其优雅的分块对角矩阵(Block-Diagonal Matrix)形态:
在这个高度稀疏的矩阵中,主对角线上的每一个 的小矩阵块,恰好代表了一个独立二维平面上的旋转算子。而矩阵其他非对角线位置全是 0,这在数学上提供了强有力的保证:不同的二维特征平面在旋转时绝对不会发生信息的串扰。
群论视角的优雅:正交群 的直和与范数守恒
为了更深刻地理解这个庞大矩阵的本质,我们需要借助李群(Lie Group)的视角。
在群论中,所有行列式为 1 且满足正交性质的 旋转矩阵,构成了一个连续的旋转群,称为 (2维特殊正交群,Special Orthogonal group)。这意味着,RoPE 的全维旋转矩阵 ,在代数结构上实际上是 个 群的直和(Direct Sum):
这种直和结构不仅带来了数学形式上的美感,更赋予了 RoPE 极强的工程属性——正交性保证。既然主对角线上的每个 块都是正交矩阵(即自身转置等于自身的逆),那么由它们拼合而成的分块对角矩阵 必然也是一个巨大的正交矩阵。我们可以轻易证明 (其中 是 的单位矩阵)。
为什么正交性对大语言模型如此重要?
核心在于,正交变换(纯旋转)是一种严格的等距同构(Isometry)操作。根据向量内积的性质,对于任意高维输入向量 ,经过 RoPE 编码后的 L2 范数(欧几里得长度)将保持绝对不变:
这种“范数守恒”为自注意力机制的数值稳定性提供了定海神针。在计算 Attention Score 时,我们会执行 Query 和 Key 的内积操作 。如果位置编码操作改变了向量的模长,那么随着序列长度增加或特征维度变高,内积的方差就会急剧放大或缩小,导致后续的 Softmax 激活函数极易陷入梯度消失(饱和区)或梯度爆炸。由于 RoPE 具有正交群的本质,它仅改变向量的方向,绝对不改变向量的长度,从而完美兼容了 Transformer 原生的 方差缩放机制。
迈向工程实现的巧思
在理解了 的矩阵结构后,富有经验的 AI 工程师立刻会察觉到一个性能隐患:如果每次前向传播都执行巨大的 矩阵乘法,而这个矩阵中绝大多数元素都是 0,那算力浪费将是极其惊人的。
幸运的是,分块对角的特殊结构使得我们完全不需要在显存中实例化这个庞大的 矩阵。在 Hugging Face 或 PyTorch 的底层实现中,工程师们巧妙地利用了哈达玛积(Hadamard Product,即逐元素相乘 )将这一过程极致优化:
上述公式通过对输入向量进行简单的移位取反,并结合逐元素乘加,将 的稠密矩阵乘法降维打击成了 的轻量级运算。这正是数学之美在算力世界绽放的绝佳证明。
至此,我们已经成功将二维的复平面旋转无损地推广到了高维特征空间,并从李群的角度证明了其数值计算的稳定性。但是,如果你仔细观察上述的矩阵构造,会发现一个隐藏的变量细节:每一对二维子空间使用的基础旋转频率 是不同的。
为什么作者不统一使用单一的旋转角度,而是要为每一个子空间分配各自不同的频率?这些像精密齿轮一样错落有致的 ,究竟蕴含着怎样的物理直觉?正是这种频率上的差异化设计,赋予了 RoPE 感知“相对距离远近”的超能力。我们将在下一章,通过严格的连续积分与极限推导,揭开这层名为“振荡衰减”的神秘面纱。
3. 距离感知的本质:内积的振荡衰减数学证明
在上一章中,我们从群论与矩阵分解的视角,证明了 RoPE 是 个正交二维平面的直和,这种正交性保证了向量的 范数在旋转前后守恒。这解决了“如何把绝对位置转换为相对位置”的问题。然而,对于语言模型而言,仅仅能感知“相对位置”是不够的——它还需要对位置距离的“远近”有明确的感知。
在自然语言处理中,存在一个极其重要的先验假设:局部性原理(Locality)。即距离越近的词汇(如主谓宾),其语法和语义的关联性往往越强;距离越远,关联性期望就越弱。如果 RoPE 不能在数学机制上天然契合这一先验,模型就需要耗费大量参数去硬背这种衰减规律。本章我们将深入 RoPE 的内核,用严密的数学推导证明:RoPE 的设计能够自然地实现这种随距离增加的振荡衰减(Decay Property)。
展开内积:多频干涉的数学表达
为了剥离查询向量(Query)和键向量(Key)本身语义特征的干扰,纯粹研究位置编码对注意力分数(Attention Score)的影响,我们假设词嵌入向量在各个维度上的元素是独立同分布的,均值为 0。此时,我们来考察加入 RoPE 后,第 个位置的 和第 个位置的 在点积时的数学期望。
根据上一章的分块对角矩阵形态,多维内积可以拆解为 个独立二维平面的内积之和。经过复数域或二维旋转矩阵的推导,内积结果严格依赖于相对距离 :
在期望意义下,交叉项抵消,起决定性作用的核心衰减因子 可以被抽象为多组不同频率余弦函数的简单叠加:
这里的 就是每个二维平面的旋转角频率。公式的物理意义非常直观:RoPE 下的相对位置得分,本质上是一组不同频率的正弦波在相对距离 处的干涉叠加。
频率设定的玄机:等比数列与多尺度时钟
在原论文中,作者并没有随意选择 ,而是设定了一个极其讲究的等比数列:
其中,底数 在原始 Transformer 和 LLaMA 中默认取值为 。为什么要是等比数列?为什么底数是 ?
如果将每个二维平面看作一个“时钟”的指针, 就是指针每次移动的角度(频率)。
- 当 时,频率最高,,相对距离 每增加 1,指针就旋转约 ,其波长极短,主要负责捕捉局部的精确距离变化。
- 当 时,频率最低,,相对距离增加 1,指针几乎不动,波长极长,主要负责捕捉宏观的全局位置上下文。
这种从高频到低频的指数级分布,相当于在特征空间中构建了一个多尺度定位系统。底数 决定了波长的跨度范围(从 到 ),这个跨度必须大到足以覆盖模型训练阶段的最大上下文长度,以保证在极端远距离下,最低频维度的相位仍不至于发生混叠(即转过超过一整圈)。
离散转连续:振荡衰减的严密证明
回到我们的核心问题:函数 为什么会随着 的增大而衰减?离散求和的形式难以直观洞察其极限性质,我们需要将其转化为连续空间的积分来进行分析。这也是原论文附录中给出衰减证明的关键思路。
令连续变量 ,则 。离散求和 可近似为如下黎曼积分:
为了求解这个积分,我们作变量代换。令 ,则 ,其微分 。当 时,;当 时,。积分上下限翻转,代入后得到:
这是一个极其经典的积分形式,与狄利克雷积分(Dirichlet integral)密切相关。我们来分析随着距离 增大时该积分的行为:
- 当 时(也就是 Query 和 Key 在同一个位置),所有频率的 ,发生完全相长干涉(Constructive interference),此时 取得绝对最大值 1。
- 当 逐渐增大时,积分区间 向右侧推移。被积函数 具有两个特性:一是分子 会在 之间剧烈振荡;二是分母 会使得整个包络线以 的速度收敛。
- 根据黎曼-勒贝格引理(Riemann-Lebesgue Lemma)的思想,由于高频振荡的正负面积会快速相互抵消,且包络被分母 压制,导致随着 增大,积分值整体呈现波动下降的趋势,其上界被严格约束在衰减包络线内。
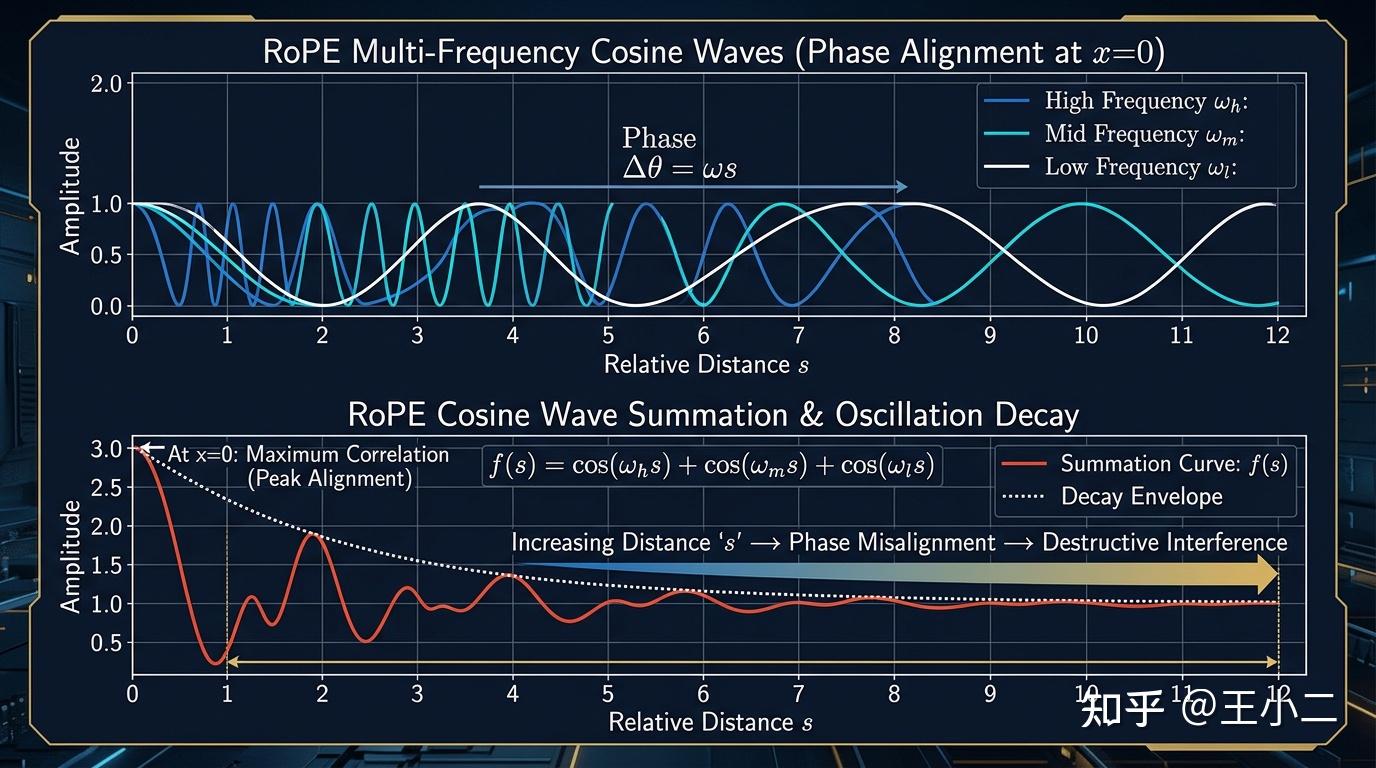
从物理直觉上理解如上图所示:在距离为 0 时,所有波峰整齐划一;一旦距离拉开,不同波长的周期曲线相位开始错乱,有的在波峰,有的在波谷,发生相消干涉(Destructive interference)。距离越远,相位错乱越严重,求和后的期望就越趋近于零。
局部性先验与长文本伏笔
这一优美的数学推导,证明了 RoPE 绝非简单的工程 trick,而是利用多维频域空间中的干涉现象,在不引入任何额外可学习参数的前提下,天然赋予了模型“距离越远,注意力期望越低”的局部性先验(Locality Prior)。这极大地降低了模型学习相对距离规律的难度。
然而,这也埋下了一个隐患:当我们试图让模型在推理时处理比训练阶段更长的文本(即所谓的长度外推)时,最大的相对距离 将突破训练时的分布。这会导致那些在训练中从未转过大角度的“低频指针”,在推理时突然转到了未知的相位区域,从而彻底破坏了注意力分数的衰减规律和原始的波峰分布。这就是引发长文本“外推灾难”的根本数学原因。
如何化解这一危机?既然位置编码的本质是频率域的波长分布,我们能否直接在频率上做文章?下一章,我们将跨入当前 LLM 领域最激动人心的前沿地带:从频率域视角解析 NTK-aware 与 YaRN 等突破长度极限的数学魔法。
4. 突破长度极限:频率域视角的 NTK 缩放与 YaRN 外推
在上一章中,我们通过积分与极限证明了 RoPE 的内积期望会随着相对距离的增加而呈现振荡衰减,这赋予了模型在训练窗口 内卓越的距离感知能力。然而,当工程师们试图将大语言模型(LLM)应用于超长文本时,却遭遇了一堵无形的墙——长度外推灾难(Context Length Extrapolation Disaster)。
为什么模型一旦越过训练长度,性能就会呈现断崖式下跌?更重要的是,为什么我们能通过简单的数学变换(如 NTK-aware 缩放与 YaRN),在极少甚至不重新训练的情况下,瞬间将模型的上下文窗口扩大数倍?这一切的答案,都藏在 RoPE 的频率域之中。
外推灾难的数学本质:未知的巨大旋转角
大模型的外推能力差,本质上是一个分布外(Out-of-Distribution, OOD)问题。
回想第一章的欧拉公式推导,Query 和 Key 的相对位置分数依赖于旋转角度 。在预训练阶段,模型见过的最大相对距离是 (例如 4096)。这意味着,对于任何一个频率维度 ,模型所适应并优化过的最大旋转角度上限为 。
当推理时的文本长度超过 (比如 时),低频维度(较小的 )会产生一个模型在训练时从未见过的巨大相位差。在复平面的几何直觉中,这就好比模型只学会了如何识别钟表指针在 0 到 180 度之间的夹角含义,一旦夹角跑到 270 度,投影(内积)的值域和梯度都会发生剧烈畸变。原有的注意力分布规律被彻底破坏,模型因此陷入混乱,输出乱码。
频率域视角:高频看细节,低频看宏观
要解决这个问题,我们必须跳出单纯的“相对距离”视角,将位置编码视为一种多频信号的频谱分布。
RoPE 设定了一组呈等比缩放的旋转频率:,其中底数通常为 。根据这个公式,高维空间被巧妙地划分成了不同职责的频段:
- 高频分量(较小的 ): 很大,随着位置 的增加,复平面上的向量旋转得极其剧烈(波长极短)。它们负责捕捉极小范围内的局部相对位置,例如相邻的词语构成的强关联语法结构。
- 低频分量(较大的 ): 极小,向量旋转得非常缓慢(波长极长)。它们负责记录宏观的篇章相对位置,比如当前词是在第一段还是第五段。
如果我们要把上下文窗口从 4096 扩展到 32768(扩大 8 倍,缩放因子 ),最粗暴的方法是位置插值(Position Interpolation, PI):直接把新的位置索引等比例压缩,令 。这相当于把超长文本硬生生“挤压”回模型熟悉的训练长度内。
但 PI 有一个致命缺陷:它对所有频率进行了无差别的压缩。这就导致高频维度原本用来区分“相邻词”的微小角度差也被缩小了 8 倍,局部特征变得极度模糊,模型出现了“近视”,丢失了精确的局部注意力。

NTK-aware 缩放:从高频失真到对数插值
既然不能动高频,那该怎么处理?神经切线核(Neural Tangent Kernel, NTK)理论提供了一个绝佳的直觉视角。
NTK 理论表明,深度神经网络在学习过程中,如果高频特征被过度扭曲,模型将极难重新学习并收敛;而对低频特征的平滑缩放则相对鲁棒。基于这一先验,NTK-aware 缩放提出了一种优雅的非线性策略:不改变高频基底,只对低频基底进行对数级别的缩放。
在数学操作上,NTK-aware 并没有直接去修改位置索引 ,而是把手术刀挥向了底数 。我们将底数放大为一个新的 :
当我们把 代回频率公式 时,神奇的数学现象发生了:
- 对于高频维度():指数项趋于 0,因此 。高频波长几乎未变,模型完美保留了局部的细节分辨率。
- 对于低频维度():缩放效应达到最大,等价于对旋转周期进行了正比于 的拉伸。
通过改变计算频率的进制(底数),NTK-aware 将频率域进行了巧妙的“扭曲”。它将原本超出模型认知的巨大旋转角“外推(Extrapolation)”,顺滑地压缩成了模型见过的“插值(Interpolation)”。这一切无需从头重训,只需微调甚至免微调(Zero-shot),就能让模型平稳过渡到超长文本。
YaRN 的进阶:波长分段与信息熵补偿
如果说 NTK-aware 是一次精妙的数学打击,那么 YaRN (Yet another RoPE extensioN) 则是彻底理顺这套理论的集大成者。
YaRN 引入了傅里叶变换的信息熵视角,放弃了单纯修改底数 这种容易产生全局连带效应的做法,而是直接以波长 为标尺,定义波长与原始训练窗口大小 的比值 ,并通过上下界超参数 和 对整个频率空间进行精确的数学分段。
通过引入 Ramp 平滑函数 ,YaRN 对不同维度的频率 进行了差异化的插值计算,最终的频率插值公式为 。具体的频段切割标准与映射关系如下表所示:
频段高频段过渡段低频段波长比例频率大小极大中等极小与上下文窗口的关系波长远小于原始窗口,推理时未超出周期范围波长与原始窗口相当,存在部分越界风险波长远大于原始窗口,超长推理必定发生严重缩放策略保持绝对不变,严禁插值基于使用函数平滑缝合彻底的线性插值压缩
更硬核的是,YaRN 站在了信息熵的高度修复了注意力机制的一个隐秘 Bug。当上下文窗口扩大 倍时,参与 Softmax 竞争的 Token 数量也随之增加了 倍。这必然导致输出的注意力分数变得更加分散、扁平(分布的信息熵变大)。为了补偿这种“失焦”,YaRN 在计算完 Attention Logits 后,直接乘以一个温度缩放因子 (在论文中经验公式设定为 ),强行锐化注意力分布,将系统的熵拉回训练时的期望水平。
通过极度严谨的频段解耦与信息熵补偿,YaRN 真正实现了近乎无损的超长上下文外推能力。
结语
从复平面上优雅的欧拉公式,到高维空间中 正交群的直和,旋转位置编码(RoPE)绝非大模型发展史上的一个偶然工程技巧,而是一场深刻的数学觉醒。本文层层剥开了 RoPE 的底层逻辑:它通过范数守恒维持了 Attention 运算的数值稳健,更绝妙地利用多频波干涉,将相对距离感知转化为连续积分视角下的振荡衰减。这不仅完美契合了语言模型对局部上下文关注的物理先验,更为我们在频率域内重塑序列维度提供了坚实的理论基石。
然而,当我们试图通过 NTK 缩放或 YaRN 算法突破上下文长度极限时,仍需正视当前的理论局限。尽管基于波长分段与平滑函数的频率插值已逼近代数设计的极致,但随着文本长度迈向百万级,超低频段的表征容量枯竭与极长距离下的相位错乱依然存在,单纯的频率映射无法彻底根除“注意力弥散”现象。此外,长序列导致的信息熵激增,目前仍依赖于经验性的温度系数(如 )进行外围补偿,尚未在注意力机制的核心公式中获得完全严密的解析解。
展望未来,位置编码的演进势必呼唤新的范式跃迁。我们能否探索出基于输入内容动态自适应的频率重组机制?或者彻底跳出余弦频率的绝对束缚,结合时频联合分析乃至状态空间理论,寻找真正具备无限外推能力的非线性几何算子?在这个被算力洪流裹挟的时代,RoPE 的成功恰恰提醒了我们:最惊艳的工程突破,往往蛰伏于最纯粹的数学与物理直觉之中。掌握了这把将几何变换映射到高维特征空间的密钥,下一个颠覆性的模型架构或许已在推导的草稿纸上隐约成型。