
前言:AI 时代的浪潮袭来,准备针对AI 的软硬件核心和基础问题开展一系列研究,跟朋友们一起探讨。
我们将介绍英伟达的 GPU 在 AI 领域的软硬件上都有着技术优势和创新:CUDA 平台和编程模型、Tensor Core 混合精度核心、Ampere 微架构和 DGX 系列产品,软硬件全方面的优势整合确定了其在 AI 硬件领域的龙头地位。传统的云服务器或者计算集群在性能、效率、成本等方面都有明显的劣势。

为什么一定要用英伟达Nvidia的GPU?
- AI 计算与 AI 服务器
AI 服务器是指专门用于执行人工智能(AI)相关的计算任务的服务器,例如深度学习、机器学习、计算机视觉、自然语言处理等。AI 服务器通常需要具备高性能、高并行度、高可扩展性和高能效等特点,以满足大规模数据处理和复杂模型训练的需求。
- GPU的特点
GPU(图形处理器)是一种专门用于处理图形相关的 并行计算任务的芯片,例如渲染、光线追踪、视频编解码等。GPU 通常具备高性能、高并行度、高吞吐量和低延迟等特点,以满足实时图形渲染和交互的需求。

英伟达(NVIDIA)在 AI 领域的技术优势
英伟达(NVIDIA)是全球最大的独立 GPU 供应商,也是 AI 芯片市场的领导者。英伟达在 GPU 领域拥有强大的技术优势和创新能力,其 GPU 在 AI 领域有以下几个方面的优势和创新:

- CUDA:CUDA(Compute Unified Device Architecture)是英伟达推出的一种通用并行计算平台和编程模型,可以让开发者利用 GPU 的强大计算能力来加速各种类型的应用计算。CUDA 提供了一套完整的软件工具和库,支持多种编程语言和操作系统,简化了 GPU 编程的难度和复杂度。CUDA 还提供了一套丰富的生态系统,包括各种深度学习框架(如 TensorFlow、PyTorch、MXNet 等)、机器学习库(如 cuDNN、cuML、RAPIDS 等)、科学计算库(如 cuBLAS、cuFFT、cuSPARSE 等)等,可以帮助开发者快速构建和部署 AI 应用程序。

- Tensor Core:Tensor Core 是英伟达在较新的微架构中专门设计的一种混合精度核心,可以在单个时钟周期内执行矩阵运算,从而大幅提升 AI 计算的效率和性能。Tensor Core 可以支持 FP16(16 位浮点数)、TF32(19 位有效位数)、BF16(16 位有效位数)、INT8(8 位整数)等不同的数据类型,并且可以自动转换精度,以适应不同的计算需求。Tensor Core 还可以与 CUDA 库和深度学习框架无缝集成,让开发者无需修改代码就可以享受 Tensor Core 带来的加速效果。
- Ampere:Ampere 是英伟达最新推出的 GPU 微架构,是 Turing 微架构的后继者。Ampere 微架构在性能、能效、可扩展性等方面都有显著提升,是目前最先进的 GPU 微架构之一。Ampere 微架构采用了台积电 7nm 工艺制造,拥有高达 54 亿个晶体管,支持高达 8 路 NVLink 3.0 高速互连,支持高达 40 GB HBM2e 高带宽显存,支持高达 600 GB/s 的显存带宽,支持高达 312 TFLOPS 的 FP16 计算能力,支持高达 1248 TOPS 的 INT8 计算能力。Ampere 微架构还引入了第三代 Tensor Core,支持新的 TF32 和 BF16 数据类型,以及稀疏矩阵运算(Sparsity),可以进一步提升 AI 计算的效率和性能。

- DGX:DGX 是英伟达推出的一系列专为 AI 训练和推理而设计的服务器和工作站产品,包括 DGX Station、DGX-1、DGX-2、DGX A100 等。DGX 系列产品集成了英伟达最先进的 GPU、NVLink、NVSwitch、NVIDIA Mellanox InfiniBand 等硬件技术,以及 CUDA、TensorRT、NVIDIA Jarvis、NVIDIA Merlin 等软件技术,提供了一站式的 AI 解决方案,可以帮助企业和研究机构快速构建和部署大规模的 AI 应用程序。
综上所述,英伟达的 GPU 在 AI 领域软硬件上都具有显著的优势和创新,可以为 AI 计算提供高性能、高并行度、高可扩展性和高能效等特点,满足大规模数据处理和复杂模型训练的需求。因此,英伟达的 GPU主导了 AI 计算的市场。
普通的云服务器或者电脑不能用来进行 AI 运算和大模型训练吗?
普通的云服务器或者电脑也可以用来进行 AI 运算和大模型训练,但是相比于使用英伟达的 GPU 的 AI 服务器,普通的云服务器或者电脑在性能、效率、成本等方面都有明显的劣势。

- 性能:普通的云服务器或者电脑通常使用 CPU(中央处理器)作为主要的计算芯片,CPU 是一种通用的计算芯片,可以执行各种类型的计算任务,但是对于 AI 相关的计算任务,CPU 的性能并不理想。AI 相关的计算任务通常涉及大量的矩阵运算、卷积运算、激活函数运算等,这些运算都是可以并行化的,也就是说可以同时执行多个相同或者相似的运算。CPU 的核心数量相对较少(通常在 4-64 之间),每个核心可以执行多个线程(通常在 2-8 之间),每个线程可以执行一个运算。因此,CPU 的并行度相对较低(通常在几十到几百之间),无法充分利用 AI 计算任务的并行性。GPU 的核心数量相对较多(通常在几百到几万之间),每个核心可以执行一个线程(通常在 1-2 之间),每个线程可以执行一个运算。因此,GPU 的并行度相对较高(通常在几千到几十万之间),可以充分利用 AI 计算任务的并行性。此外,GPU 还拥有专门设计的 Tensor Core 核心,可以在单个时钟周期内执行矩阵运算,进一步提升 AI 计算任务的性能。因此,在相同频率和功耗下,GPU 的 AI 计算性能要远远高于 CPU。
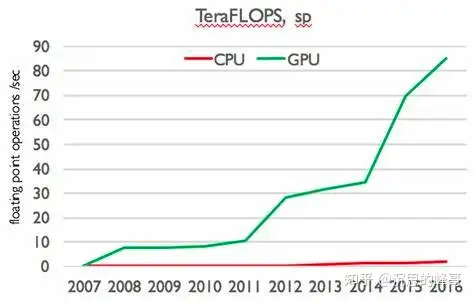
- 效率:普通的云服务器或者电脑在进行 AI 运算和大模型训练时,除了性能之外,还需要考虑效率的问题。效率是指在完成相同的计算任务时,所消耗的时间、能源、空间等资源的多少。效率越高,意味着资源的利用率越高,成本越低,环境影响越小。使用英伟达的 GPU 的 AI 服务器在效率方面也有明显的优势,主要体现在以下几个方面:
- 时间:使用英伟达的 GPU 的 AI 服务器可以在更短的时间内完成 AI 运算和大模型训练,从而提高生产力和创新速度。例如,根据英伟达官方数据,使用 8 块英伟达 A100 GPU 的 DGX A100 服务器可以在 3.5 小时内完成 BERT-Large 模型的训练,而使用 64 核心 CPU 的服务器则需要 45 天。同样地,使用 8 块英伟达 A100 GPU 的 DGX A100 服务器可以在 1.5 小时内完成 GPT-3 模型(1750 亿参数)的训练,而使用 512 核心 CPU 的服务器则需要 3.8 年。
- 能源:使用英伟达的 GPU 的 AI 服务器可以在更低的能耗下完成 AI 运算和大模型训练,从而节省电力成本和减少碳排放。例如,根据英伟达官方数据,使用 8 块英伟达 A100 GPU 的 DGX A100 服务器可以在每秒 5.07 千瓦时(kW-h)的能耗下完成 ResNet-50 模型(2.4 亿参数)的训练,而使用 64 核心 CPU 的服务器则需要每秒 28.07 千瓦时。同样地,使用 8 块英伟达 A100 GPU 的 DGX A100 服务器可以在每秒 6.22 千瓦时的能耗下完成 GPT-3 模型(1750 亿参数)的训练,而使用 512 核心 CPU 的服务器则需要每秒 130.51 千瓦时。
- 空间:使用英伟达的 GPU 的 AI 服务器可以在更小的空间占用下完成 AI 运算和大模型训练,从而节省机房空间和降低散热难度。例如,根据英伟达官方数据,使用 8 块英伟达 A100 GPU 的 DGX A100 服务器可以在每平方米(m2)0.28 千兆浮点运算数(GFLOPS)的空间占用下完成 ResNet-50 模型(2.4 亿参数)的训练,而使用 64 核心 CPU 的服务器则需要每平方米 0.02 千兆浮点运算数。同样地,使用 8 块英伟达 A100 GPU 的 DGX A100 服务器可以在每平方米 0.34 千兆浮点运算数的空间占用下完成 GPT-3 模型(1750 亿参数)的训练,而使用 512 核心 CPU 的服务器则需要每平方米 0.01 千兆浮点运算数。
因此,在相同的计算任务下,使用英伟达的 GPU 的 AI 服务器可以比普通的云服务器或者电脑节省更多的时间、能源和空间等资源,提高效率和降低成本。
- 成本:普通的云服务器或者电脑在进行 AI 运算和大模型训练时,除了性能和效率之外,还需要考虑成本的问题。成本是指在完成相同的计算任务时,所需要投入的资金的多少。成本越低,意味着收益越高,竞争力越强。使用英伟达的 GPU 的 AI 服务器在成本方面也有明显的优势,主要体现在以下几个方面:
- 硬件成本:使用英伟达的 GPU 的 AI 服务器可以在更少的硬件数量下完成 AI 运算和大模型训练,从而节省硬件采购和维护的成本。例如,根据英伟达官方数据,使用 8 块英伟达 A100 GPU 的 DGX A100 服务器可以替代 50 台 CPU 服务器来完成 BERT-Large 模型的训练,从而节省了 90
- 软件成本:使用英伟达的 GPU 的 AI 服务器可以利用英伟达提供的丰富的软件平台和工具来加速和简化 AI 应用程序的开发和部署,从而节省软件开发和优化的成本。例如,使用英伟达的 CUDA 平台和编程模型,开发者可以轻松地利用 GPU 的强大计算能力来加速各种类型的应用程序,无需修改大量的代码或者学习复杂的新技术。使用英伟达的 TensorRT 平台和工具,开发者可以轻松地将深度学习模型优化和部署到各种设备上,无需担心兼容性或者性能损失。使用英伟达的 Jarvis 平台和工具,开发者可以轻松地构建和部署多模态(语音、视觉、自然语言)的 AI 应用程序,无需从头开始搭建复杂的流程或者训练大量的数据。
- 人力成本:使用英伟达的 GPU 的 AI 服务器可以借助英伟达提供的丰富的培训和支持资源来提升 AI 开发者和用户的技能和知识,从而节省人力招聘和培训的成本。例如,使用英伟达的 DLI(Deep Learning Institute)平台和课程,开发者和用户可以在线学习各种 AI 相关的技术和应用,从基础到进阶,从理论到实践,从图像到语音到自然语言等。使用英伟达的 NGC(NVIDIA GPU Cloud)平台和资源,开发者和用户可以获取各种预训练好的深度学习模型、容器化的软件应用、优化过的代码示例等,从而快速启动和验证自己的 AI 项目。
因此,在相同的计算任务下,使用英伟达的 GPU 的 AI 服务器可以比普通的云服务器或者电脑节省更多的硬件、软件和人力等资源,降低成本和风险。
现在整个AI产业大规模采购 Nvidia GPU 造成严重短缺的情况下,Nvidia 获得更多现金流投入研发生产,其技术实力和成本未来会更有竞争优势,其他厂商想要挑战其优势恐怕是非常困难的。