
1. CUDA
1.1 什么是CUDA
CUDA全称(Compute Unified Device Architecture)统一计算架构,是NVIDIA推出的并行计算平台,它提供了相关API让开发者可以使用GPU完成通用计算加速(GPGPU),而不仅仅是图形计算
1.2 GPU
1.2.1 图形加速
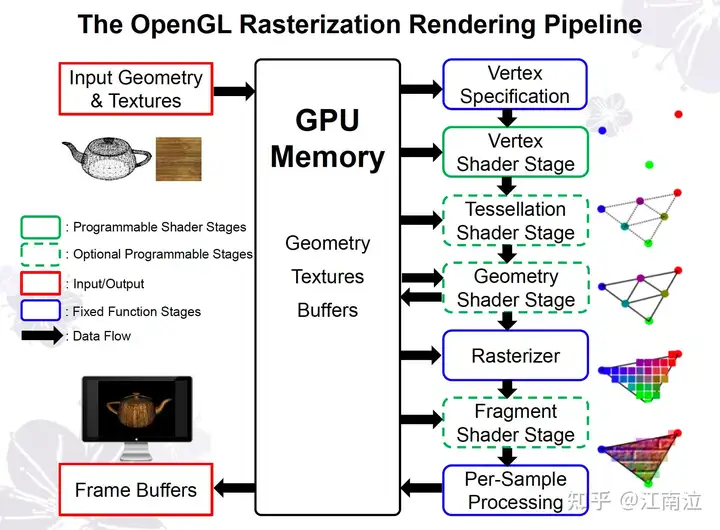
自1999 年推出的 GeForce 256以来,GPU(Graphics Processing Unit)一直是以图形处理为主,大幅提升了图形光栅化的处理速度。

1.2.2 深度学习加速
对于神经网络,无论是离线训练还是在线推理,都有巨量的矩阵、归一化、softmax等运算,且其中有非常多的并行计算,非常适合用GPU来进行运算加速。
2. CUDA 异构计算
2.1 异构计算(heterogeneous computing architectures)
- 同构计算:使用相同类型指令集和体系架构的计算单元组成系统的计算方式(纯CPU)。
- 异构计算:使用不同类型指令集和体系架构的计算单元组成系统的计算方式,如CPU、GPU、FPGA等,并将它们协同工作以达到更高效的计算目的。这种方式可以充分利用每种处理器的独特优势,从而提高计算性能和功率效率。
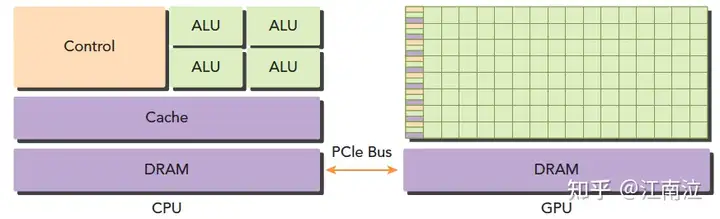
上图是CPU和GPU设备配合的异构计算架构,两者通过PCIe总线连接,用于传递指令和数据,代码也分为两部分:
- 主机代码:在主机端运行,被编译成主机架构的机器码
- 设备代码:在设备上执行,被编译成设备架构的机器码
所以主机端的机器码和设备端的机器码是隔离的,自己执行自己的,没办法交换执行。主机端代码主要是控制设备,完成数据传输等控制类工作,设备端主要的任务就是计算。
2.2 并行性
并行有两种类型:
- 任务并行:并行请求、ha3分列查询
- 数据并行:计算过程比较单一(不同的数据基本用相同的计算过程)但是数据非常多,矩阵运算
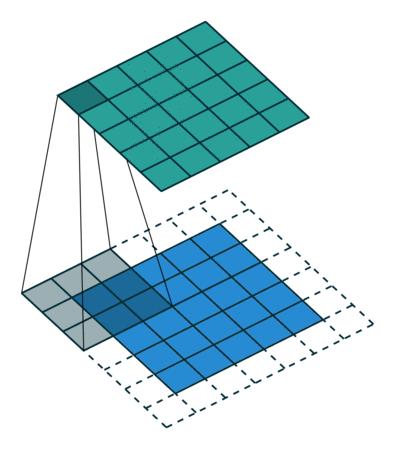
CUDA非常适合数据并行型编程,而数据并行程序设计,第一步就是把数据依据线程进行划分,通常划分数据有两种方式:
- 块划分:每个线程各自分得一整块连续的数据
- 循环划分:每个线程循环分得数据(i、i+n、i+2n…)
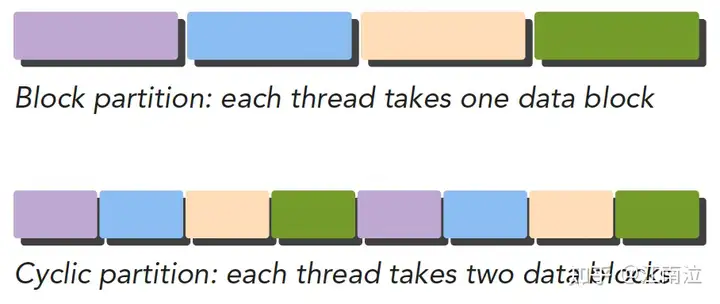
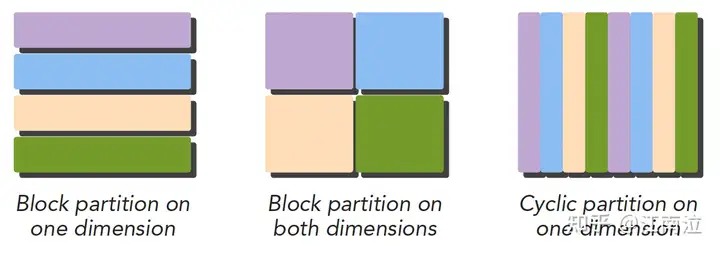
虽然数据从逻辑上可以划分为多维,但是实际上都是以一维的形式物理存储的,如何将数据划分给线程我们需要同时考虑数据的物理存储,以及线程的执行顺序。不同的数据划分严重影响程序性能,所以针对不同的问题和不同计算机结构,我们要通过和理论和试验共同来决定最终最优的数据划分。
2.3 计算机架构
2.3.1 Flynn’s Taxonomy
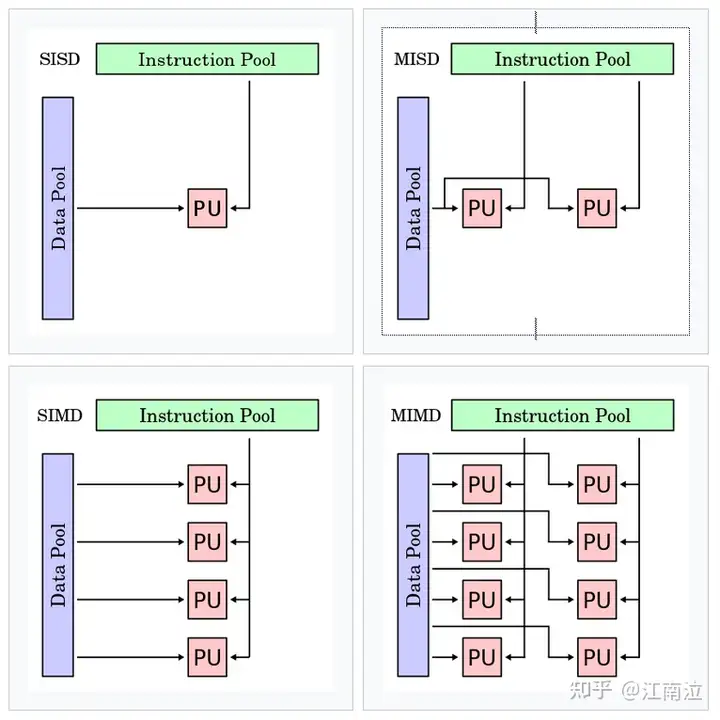
佛林分类法Flynn’s Taxonomy,根据指令和数据进入CPU的方式对计算机架构进行分类,分为以下四类:
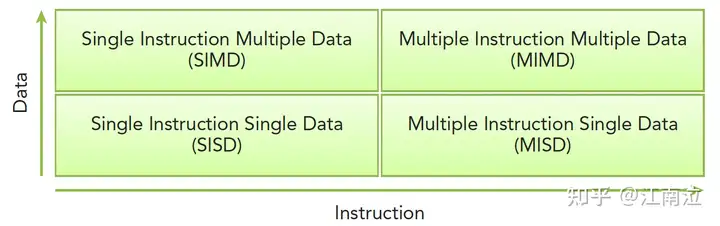
- 单指令单数据 (SISD):传统的单核处理数据方式
- 单指令多数据(SIMD):单核执行一条指令完成多数据处理(游戏中向量、矩阵)
- 多指令单数据 (MISD):多核执行不同的指令处理单个数据(少见)
- 多指令多数据 (MIMD):多核执行不同的指令处理多个数据
为了提高并行的计算能力,我们要从架构上实现下面这些性能提升:
- 降低延迟(latency):指操作从开始到结束所需要的时间,一般用微秒计算,延迟越低越好
- 增加带宽(bandwidth):单位时间内处理的数据量,一般用MB/s或者GB/s表示
- 增加吞吐(throughput):单位时间内成功处理的运算数量,一般用gflops来表示(十亿次浮点计算)
2.3.2 内存划分
不同的内存组织形式也可以划分计算机架构类型
- 分布式内存的多节点系统:集群,各个机器之前通过网络进行数据交互
- 共享内存的多处理器系统:包括单片多核,多片多核
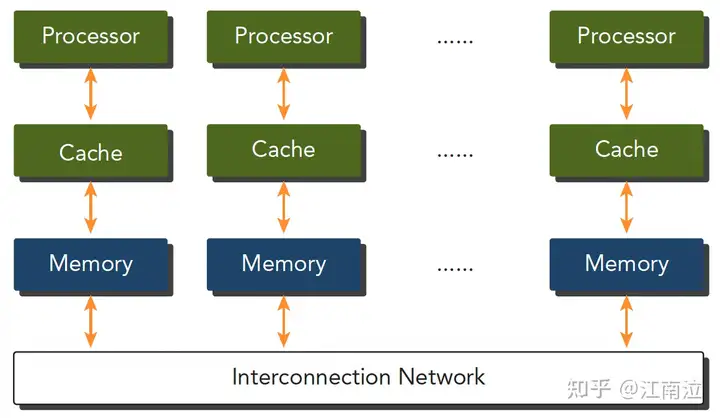
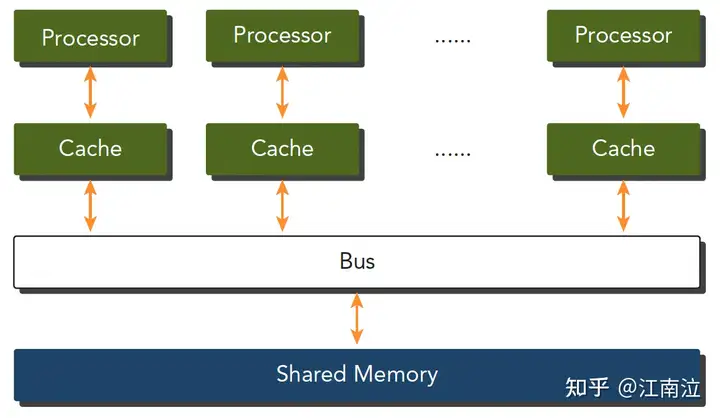
GPU是众核架构,表述为Single Instruction, Multiple Thread (SIMT),不同于SIMD,SIMT是真正的启动了多个线程,执行相同的指令,去完成数据的并行运算。
3. CUDA编程模型
3.1 CUDA编程结构
CUDA编程让你可以在CPU-GPU的异构计算系统上高效执行应用程序,语法只是在C语言的基础上做了简单的扩展,在开始编程前,我们首先得理清Host和Device的概念
- Host:CPU及其内存
- Device:GPU及其内存
运行在GPU设备上的代码我们称为kernel
典型的CUDA程序处理流程:
- 分配内存,数据初始化
- 将数据从Host拷贝到Device
- 调用kernels处理数据,然后存在GPU内存(Device)
- 将数据从Device拷贝到Host
- 内存释放
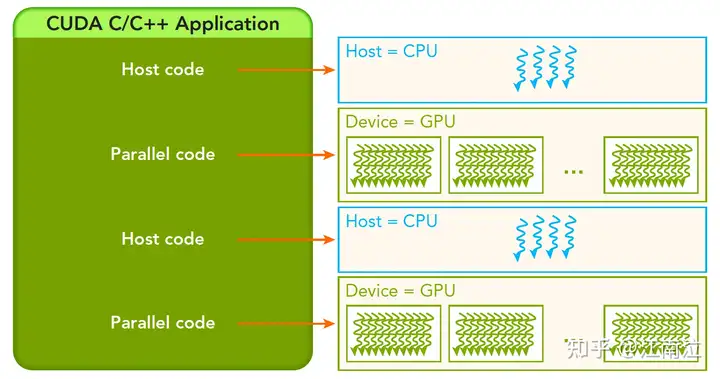
3.2 内存管理
| 标准C函数 | CUDA 函数 | CUDA函数说明 |
| malloc | cudaMalloc | GPU内存分配 |
| memcpy | cudaMemcpy | 用于Host和Device之间数据传输 |
| memset | cudaMemset | 设定数据填充到GPU内存中 |
| free | cudaFree | 释放GPU内存 |
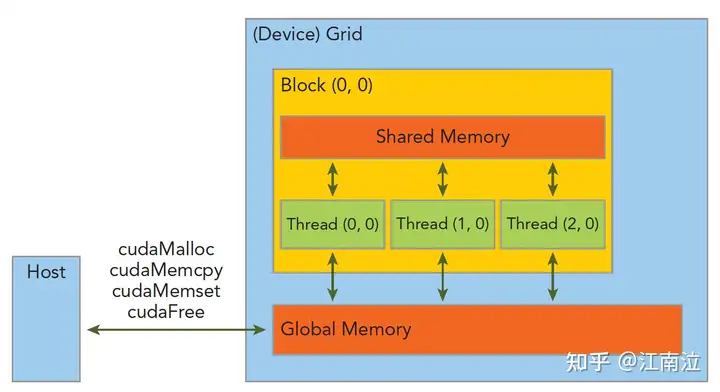
3.3 线程管理
3.3.1 Grid&Block
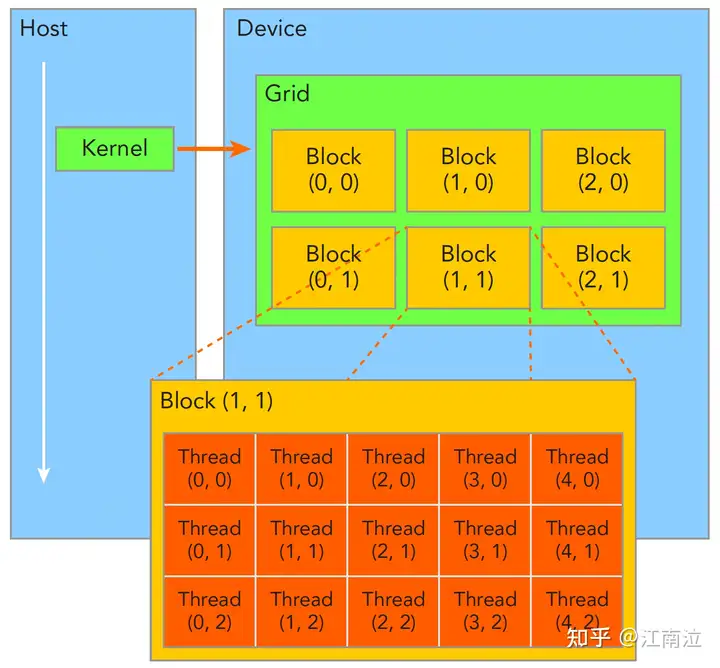
- 一个Kernel所launch的所有线程称为grid,他们共享相同的全局内存空间(global memory space)
- 一个grid由多个block(线程块)组成,block内部的线程可以通过以下两点进行协作(不同block间的线程不能协作)
- block本地同步(synchronization)
- block本地共享内存(sharedmemory)
- 一个线程通过blockIdx(grid内的index)和threadIdx(block内的index)这两个坐标变量(三维类型unit3)来唯一标识(线程运行的时候这两个变量会被CUDA赋上相应的坐标值,可以直接使用)
- grid和block的维度信息通过gridDim和blockDim(dim3)来表示
- gridDim:表示一个grid里面有多少个blocks
- blockDim:表示一个block里面有多少个threads
- dim3是手工定义的,主机端可见。uint3是设备端在执行的时候可见的,不可以在核函数运行时修改,初始化完成后uint3值就不变了
3.3.2 kernel
不同于C语言中函数的调用,CUDA的内核函数调用时需要指定总的线程数量,以及相应的线程布局(grid和block维度配置)
// C函数
function_name (argument list);
// CUDA kernel call
kernel_name<<<4, 8>>>(argument list);
3.3.2.1 限定符
因为数据在全局内存中是线性存储的,所以可以通过blockIdx.x和threadIdx.x来标识grid中的线程,建立线程和数据之间的映射关系。
核函数限定符的意义如下:
| 限定符 | 执行 | 调用 | 备注 |
| __global__ | Device执行 | Host调用/Device调用 | 必须有一个void的返回类型 |
| __device__ | Device执行 | Device调用 | |
| __host__ | Host执行 | Host调用 | 可以省略 |
接下来通过两个向量A和B的相加操作来看下GPU编程的不同之处
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int i = 0; i < N; i++)
C[i] = A[i] + B[i];
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
sumArraysOnGPU<<<1, N>>>(A, B, C);
...
}3.3.2.2 nvprof
可以通过nvprof来统计性能,数据传输
Type Time(
GPU activities: 44.49
35.59
19.92
API calls: 99.71
0.15
0.05
0.04
0.02
0.01
0.01
0.00
0.00
0.00
0.00
0.00
4. CUDA执行模型
4.1 GPU架构概览
GPU架构就是由可扩展的流式多处理器(Streaming Multiprocessors简称SM)阵列所构建,整个硬件的并行就是不断复制这种架构实现的。通常每个GPU都有多个SM,每个SM都支持上百个线程的并行,所以GPU可以支持上千个线程的并行。
接下来我们先看下SM中的核心部件:
- CUDA Cores:核心,是最小的执行单元
- Shared Memory/L1 Cache:共享内存和L1缓存,他们共用64KB空间,根据Bl
- Register File:寄存器,根据线程划分
- Load/Store Units:16个数据读写单元,支持16个线程一起从Cache/DRAM存取数据
- Special Function Units:4个特殊函数处理单元,用于sin/cos这类指令计算
- Warp Scheduler:Warp调度器,所谓Warp就是32个线程组成的线程束,是最小的调度单元
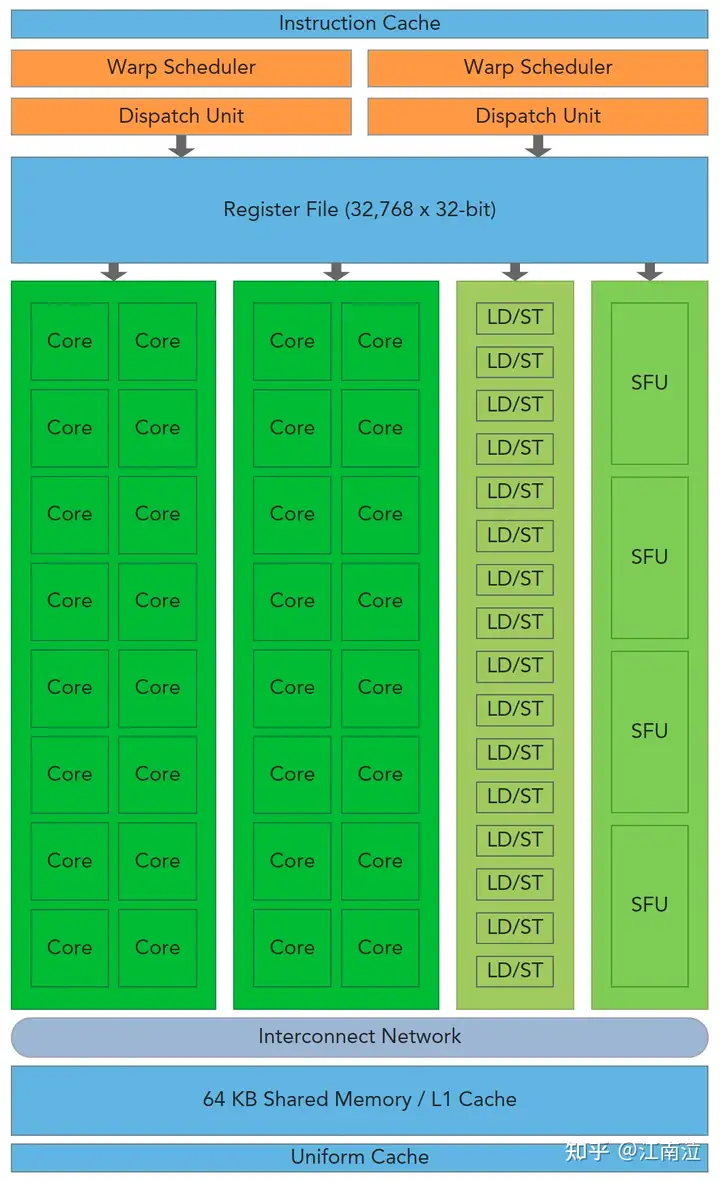
Fermi SM 了解了SM之后,我们进一步探究下kernel是如何使用SM进行并行运算的。
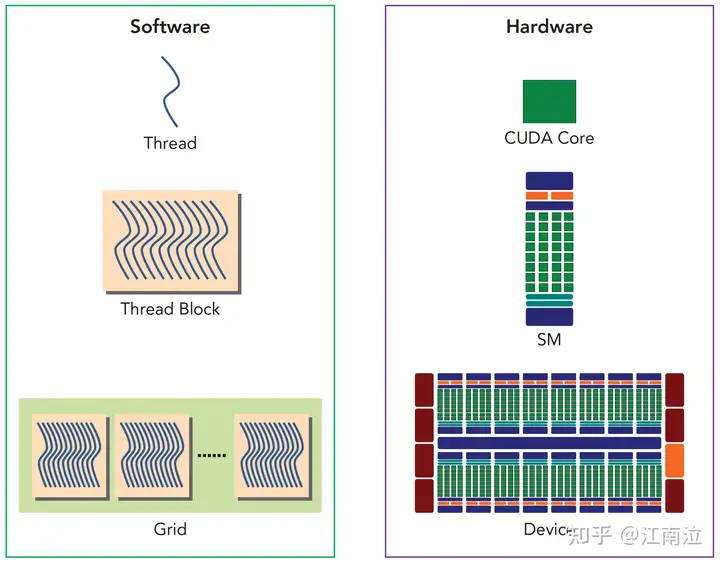
每个kernel调用都会起一个Grid,Grid中有很多线程块,每个Block都会被分配到可用的SM上执行(不能重绑),Block中的线程会被划分为多个Warp用以调度运行,SM内部通过两个Warp调度器和两个指令分发单元实现warps的调度,同一时刻,会并发运行两个warp,每个warp会被分发到一个Cuda Core Group(16个CUDA Core), 或者16个load/store单元,或者4个SFU上去真正执行,且每次分发只执行一条指令,在Fermi架构中每个SM可以同时处理48个warp。
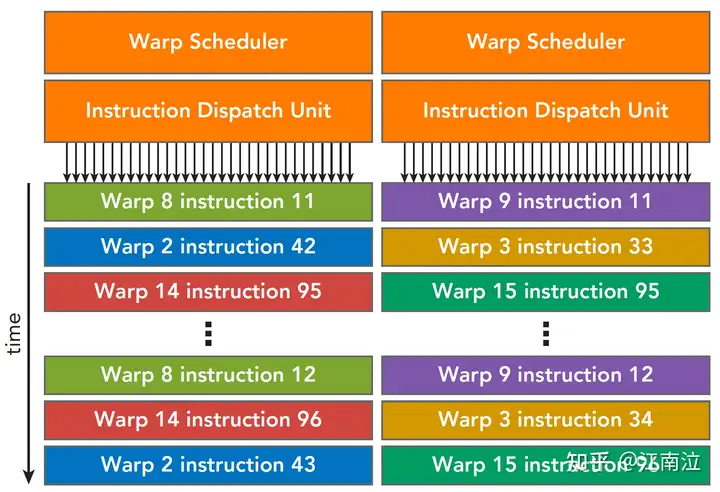
Fermi SM Warp调度 4.2 线程束分化
我们知道Warp执行是遵循SIMT(单指令多线程)规约的,所以同一时刻,Warp中的所有线程接收到的指令都是相同的,但是如果线程运行时代码存在如下所示的条件分支时,就会发生线程束分化(Warp Divergence),也就是说每个线程的执行路径不再相同
if (cond) {
...
} else {
...
}
此时if条件满足的线程就会一起执行,另外的线程则先等待;等它们执行完成后,其余线程再统一执行else中的逻辑,整体执行如下图所示
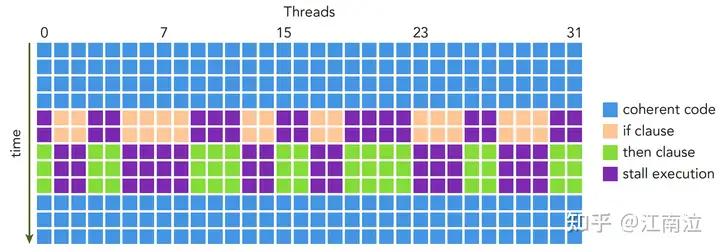
Warp Divergence Execute 由此可以发现,分化越多(条件分支越多),线程束并行性削弱越严重,所以我们需要尽量让执行相同路径的线程塞到同一个线程束中。接下来我们看一个简单的warp divergence优化例子
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if (tid
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
// 不开启优化编译
nvcc -g -G -arch=sm_60 warp_divergence.cu -o warp_divergence
// 统计分支效率
nvprof --metrics branch_efficiency ./warp_divergence
// 统计divergence数量
nvprof --events branch,divergent_branch ./warp_divergence
Invocations Event Name Min Max Avg Total
Device "Tesla P100-PCIE-16GB (0)"
Kernel: mathKernel1(float*)
1 branch 1552 1552 1552 1552
1 divergent_branch 2 2 2 2
Kernel: mathKernel2(float*)
1 branch 11 11 11 11
1 divergent_branch 0 0 0 0
5. CUDA内存模型
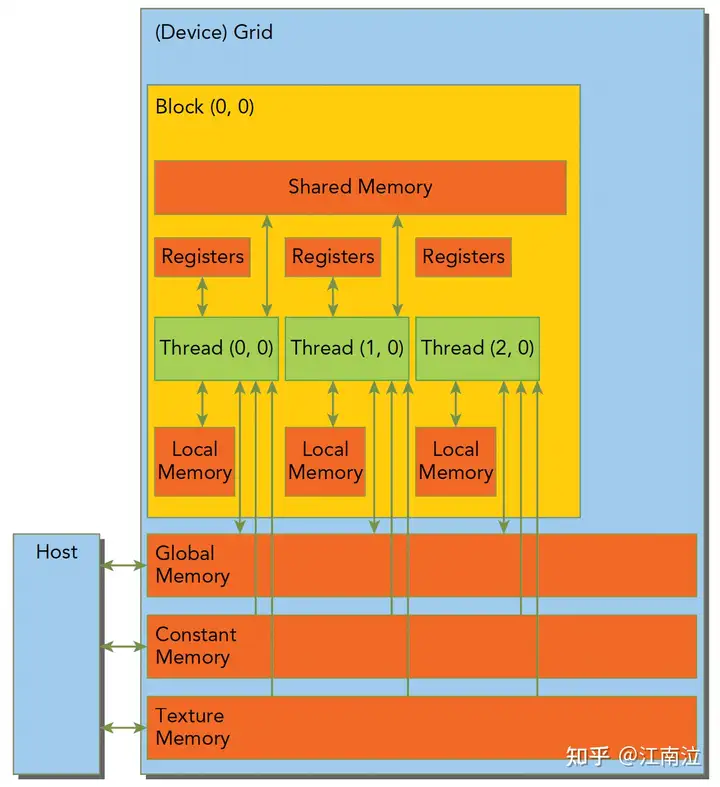
5.1 GPU内存
- 寄存器:GPU上访问最快的存储空间,是SM中的稀缺资源,对于每个线程是私有的,Fermi架构中每个线程最多63个,Kepler结构扩展到255个。如果变量太多寄存器不够,会发生寄存器溢出,此时本地内存会存储多出来的变量,这种情况对性能影响较大。
- 本地内存:本质上是和全局内存放在同一块存储区域中(compute capability 2.0以上的设备,会放在SM的一级缓存,或者设备的二级缓存上)具有高延迟、低带宽,编译器可能会将以下变量存放于本地内存:
- 编译时期无法确定索引引用的本地数组
- 可能会消耗大量寄存器的较大本地数组/结构体
- 任何不满足核函数寄存器限定条件的变量
- 共享内存:因为是片上内存,所以相比全局内存和本地内存,具有较高的带宽和较低的延迟
- SM中的一级缓存,和共享内存共享一个64k的片上内存,L1不可编程,共享内存可以
- 切勿过度使用共享内存,导致部分线程块无法被SM启动,影响Warp调度
- 可以使用__syncthreads()来实现Block内线程的同步
- 常量内存:驻留在设备内存中,每个SM都有专用的常量内存缓存
- 常量内存在核函数外,全局范围内声明,对于所有设备,只可以声明64k的常量内存
- 核函数无法修改,Host端使用cudaMemcpyToSymbol接口初始化
- 纹理内存:驻留在设备内存中,在每个SM的只读缓存中缓存,对于2D数据的访问性能较好
- 全局内存:GPU上最大的内存空间,延迟最高,使用最常见的内存,访问是对齐访问,也就是一次要读取指定大小(32,64,128)整数倍字节的内存,所以当线程束执行内存加载/存储时,需要满足的传输数量通常取决与以下两个因素:
- 跨线程的内存地址分布
- 内存事务的对齐方式。
修饰符 变量名称 存储器 作用域 生命周期 float var 寄存器 线程 线程 float var[100] 本地 线程 线程 __share__ float var* 共享 块 块 __device__ float var* 全局 全局 应用程序 __constant float var* 常量 全局 应用程序
存储器 片上/片外 缓存 存取 范围 生命周期 寄存器 片上 n/a R/W 一个线程 线程 本地 片外 1.0以上有 R/W 一个线程 线程 共享 片上 n/a R/W 块内所有线程 块 全局 片外 1.0以上有 R/W 所有线程+主机 主机配置 常量 片外 Yes R 所有线程+主机 主机配置 纹理 片外 Yes R 所有线程+主机 主机配置
5.2 GPU缓存
与CPU缓存类似,GPU缓存不可编程,其行为出厂是时已经设定好了。GPU上有4种缓存:
- 一级缓存:每个SM都有一个一级缓存,与共享内存公用空间
- 二级缓存:所有SM公用一个二级缓存
- 只读常量缓存:每个SM有
- 只读纹理缓存:每个SM有
与CPU不同的是,CPU读写过程都有可能被缓存,但是GPU写的过程不被缓存,只有加载会被缓存!
参考链接
https://book.douban.com/subject/24773399/
Professional CUDA C Programming pdf
根据Professional CUDA C Programming翻译整理的博客
发布于 2023-06-08 09:45・IP 属地浙江